Nicky nacky nooo, today’s output is a bit like a legacy codebase—sluggish, slightly painful to deploy, and deeply concerning to stakeholders. But we push through!
The sky above the open-plan office was the color of a television tuned to a dead Slack channel.
Welcome to the End Times, where the transition to Agile wasn’t just a methodology shift; it was a physical cataclysm. We don’t build software anymore. We sacrifice our fleeting mortality on the altar of the Jira Board of Infinite Despair, praying to a pantheon of gods who look remarkably like middle management in fleece gilets.
The Coven of Delivery
At the center of the ritual stands the Project Manager. Or, as she is known in the ancient texts, The Wicked Witch of the North (London). She doesn’t track progress; she hexes it. Armed with a broomstick fashioned from recycled standing-desk components and a cauldron bubbling with toxic positivity, she stirs the project scope.
“Double, double, toil and trouble; Fire burn, and scope creep bubble,” she cackles, adding another layer of uncosted compliance to the sprint.
To her, the team is not a collection of humans, but a harvest of “resources” to be drained of life force. If a developer dies at their keyboard, she simply updates their capacity to 0.5 FTE for the remaining days of the cycle.
The Architects of the Illusion
Then we have the Technical Architect. A man whose understanding of infrastructure is entirely theoretical, like quantum physics or a fair day’s pay. He stands before the whiteboard, a visionary in a faded Game Cat t-shirt, eyes glazed over with the absolute certainty of the profoundly misinformed.
“We shall build it on Drupal!” he proclaims, his voice echoing through the dystopian wasteland of the server room. “And we shall pay our tithes to Acquia, the Great Sovereign and Sole Creator of the Druplicon!”
A hush falls over the room. Somewhere in the distance, an open-source contributor weeps into a cold cup of mate. To point out that Acquia does not, in fact, own Drupal is to commit heresy. It is to invite the Witch’s wrath. He believes Acquia created Drupal the same way he believes Elon Musk personally welded every Tesla with his bare hands. He is an architect of sandcastles built on a digital tide.
The HND High School Musical
Guiding this ship of fools through the digital wasteland is our resident Product Owner. Rather than offering anything resembling guidance or coherent speech, she exists in a state of perpetual, low-frequency moaning—an atmospheric dread that only occasionally coalesces into shrill, frantic demands for “timelines” and “process.” She sits at the helm of a product she couldn’t identify in a police lineup, nested within a business model she understands with the same depth a golden retriever understands quantum cryptography. While she performs Olympic-level feats of executive sycophancy—positioning her tongue with terrifying, heat-seeking precision up the backside of any passing director—she couldn’t tell you how a flesh-and-blood user actually interacts with her digital empire. In fact, what is the product? She doesn’t know. The developers don’t know. God has long since left the Slack channel. It is a ghost ship of useless deliverables, steered by a silent, parasitic captain whose only compass is the proximity of executive favour and the relentless, soul-crushing beat of a fictional project plan.
The entire team runs Scrum not like an enterprise operation, but like a group of hungover students trying to wing a Higher National Diploma group project at 3:00 AM.
The Backlog Grooming is just a collective shrug.
The Story Points are completely arbitrary—Fibonacci numbers used like tarot cards to predict a future that will never happen. “I give this login button an 8, because 8 looks like two little eyes crying.”
The Retro is a mandatory hostage situation where everyone writes “More biscuits please” on a virtual Post-it note while the world burns outside.
The Game Cat Philosophy
As the great digital deity Game Cat once purred from the top of a warm mainframe: “A mouse in the paw is worth two in the backlog, but a mouse that has been properly story-pointed can be chased for eternity without ever being caught.”
We are all just mice in the grand, dystopian simulation. We sprint and we sprint, yet we remain entirely stationary, trapped in a loop of continuous deployment to an audience of ghosts.
Now, go forth and log your hours. The Witch is watching, and the burndown chart must bleed.
I spent my 1980s summers deep in the American belly of the beast. We aren’t talking about the polished, postcard version. We’re talking about the real, tactile madness: navigating the mosquito-thick, hyper-humid air of Louisiana, escaping to the cedar lake houses, sailing, and endless bike treks of Michigan, and baking under the blinding Pensacola sun where empty white beaches collided with glowing neon strips and the glorious, beep-booping sanctuary of video game arcades.
It was the America of Stranger Things before it became a streaming commodity. We rode BMX bikes and endured bruised shins, drank soda that could probably dissolve copper, and spent ungodly hours in wood panelled basements rolling twenty-sided dice to defeat multi-headed demons.
It felt infinite. It felt like a campaign that would never end.
And look at the calendar—we are right on the cusp of Father’s Day. Back then, Father’s Day meant buying your dad a cheap tie, helping him mow a lawn that smelled like fresh-cut gasoline, and watching him drink a warm beer while staring off into the middle distance.
But as the U.S. panics over its upcoming 250th birthday, we need to talk about the country’s other fathers. The Founding Fathers. The ultimate Dads of the Republic.
In 1776, these guys were the ultimate Dungeon Masters. They rolled up a high-fantasy character named The United States, maxed out its Liberty stats, dumped all its points into Ambition, and launched a massive, continent-spanning campaign. They wrote the rulebook on a single piece of parchment, signed it with flourishes that screamed “I have a lot of feelings about tea taxes,” and then did what any classic deadbeat dad does: they walked out out to buy a pack of cigarettes and never came back.
They left us with a massive backlog, a heavily flawed campaign setting, and zero instructions on how to patch the code when the server eventually caught fire.
Now, according to the latest Reuters poll, 40% of the players think the game is over before the next milestone, and 64% say the core mechanics are completely broken.
What went wrong? Simple. The tech bros and the corporate consultants took over the table.
They looked at this beautiful, chaotic, 250-year-old D&D campaign and said, “This isn’t scalable. The Founding Fathers left a completely broken Definition of Done, we have zero velocity metrics, and the baseline architecture is a monolith. We need to force this legacy codebase into a multi-team Scaled Agile framework immediately.”
Suddenly, the pursuit of happiness was thrown into a multi-year Product Backlog, prioritised by a committee of completely detached Stakeholders. Freedom of speech became a non-functional requirement trapped in a perpetual refinement loop. The Bill of Rights? Rebranded as a Minimum Viable Product that hasn’t seen a single feature deployment since the Bill of Rights 2.0 patch in 1791.
George Washington and Thomas Jefferson set up a majestic, multi-century vision, but the current Product Owners forgot to do a single Sprint Retrospective. The backlog of national impediments—crumbling infrastructure, societal existential dread, and the fact that cheese comes out of an aerosol can—is completely infinite. Nobody is grooming the queue. The Developers are screaming at each other during the Daily Scrum, the elite Stakeholders are hoarding all the value points, and the entire system is choked by technical debt from the 20th century that nobody knows how to refactor without crashing the core database.
Worse still, the human Dungeon Master has been fired to cut costs. The Scrum Master has been replaced by a rogue AI that doesn’t understand the rules of the game and only speaks in passive-aggressive corporate threats.
System Update:“To optimise synergy for the 250th Anniversary, individual player autonomy has been deprecated. Please report to your assigned cubicle-dungeon for daily stand-up. Missing your KPIs will result in immediate banishment to the Neo-Texas Wasteland. Have a productive Father’s Day.”
When we look at the polarising pageantry of the upcoming quarter-millennium birthday, it’s not that we hate the country. It’s that we miss the original campaign. We miss the America where the monsters stayed in the Upside Down, or at least at the bottom of the suburban basement stairs, contained by a plastic grid and a handful of polyhedral dice.
Now, the monsters are running the board meeting. They wear tailored suits, they use words like “pivot” and “synergy,” and they’re trying to monetize the air we breathe.
So, if you’re celebrating this July, do it 80s style. Grab a D20. Hug your local American friend—they are trapped in the ultimate bad simulation, dealing with the ultimate multi-century daddy issues. And if the AI Scrum Master tries to sunset the entire country before the next sprint cycle, just remember: you can always try to roll for initiative.
I’m writing to you from the foggy ruins of my mind, or as it’s legally known now, the local WeWork-turned-Soylent-dispensary. My weariness amazes me. I am branded on my feet (quite literally; the new Nike-Tesla smart-socks refuse to come off until I reach my daily step quota). I have no one to meet. And my ancient empty street is too dead for dreaming, mostly because the Amazon delivery drones keep shining spotlights through my window at 3:00 AM, looking for anyone still harboring “unlicensed human thoughts.”
But enough about my existential rot. Let’s talk about democracy.
Specifically, I’d like to extend a warm, highly-monitored thank you to everyone who participated in casting their vote in the 2026 Scrum Alliance Board of Directors: Member Elected Director Election.
What a thrilling time to be alive and certified. I haven’t felt this rush of civic duty since I voted on which automated corporate apology template the local water board should use after the great microplastic leak of ’24. We did it, team. We voted for a new Director. We aligned our synergy. We estimated our story points in the face of the abyss.
Of course, the irony isn’t lost on the three remaining organic developers left in the basement. Scrum, my dear faded friends, has officially completed its beautiful, grotesque caterpillar-to-butterfly transformation. It is the new Waterfall process. It is process for the sake of process. It is a massive, self-sustaining bureaucratic ecosystem designed entirely to justify the jobs of people who wear quarter-zips and use the word “blocker” as a personality trait.
Because let’s face it: AI does most of the Product team work these days. Heck, it even does the dev work.
While the LLMs are furiously churning out perfect, unfeeling, soulless code in milliseconds, twenty human beings are still gathered around a digital whiteboard, arguing about whether a Jira ticket constitutes a 3-point or a 5-point effort. It’s magnificent. The machines are building the matrix, and we are still doing our Daily Standup to discuss on which day to do a release and who needs to sign that off even though they have no idea what is in the release.
Hey, Mr. Scrum Master Man, play a song for me.I’m not sleepy, and there is no place I’m going to. (Mainly because the orbital traffic is backed up.)
Which brings me to the biggest circus sand of the week: the SpaceX IPO.
Yes, Elmo has finally decided to let us peasants buy a fractional share of his magic swirlin’ ship. The prospectus dropped yesterday, and it’s a masterpiece of dystopian fiction. My senses have been stripped, my hands can’t feel to grip the mouse tightly enough to hit “BUY” before the trading bots inflate the price by 4000%.
The IPO promises to take us disappearing through the smoke rings of our minds, straight past the frozen leaves of Earth’s dead ecosystem, and right out to the windy beaches of a terraformed Mars. Tickets are as low as $24 (plus a $15,000,000 launch fee, convenience tax, and a mandatory subscription to premium oxygen).
I’m ready to go anywhere. I’m ready for to fade into my own parade. Cast your dancing Elon spell my way, I promise to go under it. Who needs a pension when you can own 0.00001% of a Starship booster currently rattling its way toward the asteroid belt?
If you look up at the night sky right now, you might hear laughing, spinning, swinging madly across the sun. It’s not aimed at anyone. It’s just Starlink satellites escaping on the run. And, but for the sky, there are no fences facing—mostly because SpaceX bought the rights to the stratosphere last Tuesday.
If you hear vague traces of skipping reels of rhyme while you stare at your portfolio bleeding red, don’t worry. It’s just a ragged clown behind. I wouldn’t pay it any mind. It’s just the ghost of the 20th-century economy he’s chasing.
So, let us raise a glass of synthetic nutrient fluid to the future. A future where AI writes the code, humans manage the boards, the Scrum Alliance holds elections for positions that govern nothing, and we can all buy stock in a rocket ship while our toes are too numb to step.
Let us dance beneath the diamond sky with one hand waving free—silhouetted by the rising sea, circled by the circus sands of late-stage capitalism. With all memory and fate driven deep beneath the waves.
Let me forget about today until tomorrow. Or at least until the next Sprint planning meeting.
In the jingle jangle mornin’, I’ll come followin’ you.
We’ve identified the enemy. It is the Activity Demon, the creature that feeds on the performance of work and starves the business of results. We know its weakness: the cold, hard language of the balance sheet.
Now, we move from defence to offence.
A resistance cannot win by writing a better play; it must sabotage the production itself. For each of the five acts in the SHAPE framework, there is a counter-measure—a piece of tactical sabotage designed to disrupt the performance and force reality onto the stage. This is the saboteur’s handbook.
Sabotage Tactic #1: To Counterfeit Strategic Agility… Build the Project Guillotine. The performance of agility is a carefully choreographed dance of rearranging timelines. The sabotage is to build a real consequence engine. Every project begins with a public, metric-driven “kill switch.” If user adoption doesn’t hit 10% in 45 days, the project is terminated. If it doesn’t reduce server costs by X amount in 90 days, it’s terminated. The guillotine is automated. It requires no committee, no appeal. It makes pivoting real because the alternative is death, not just a rewrite.
Sabotage Tactic #2: To Counterfeit Human Centricity… Give the Audience a Veto. The performance of empathy is the scripted Q&A where softballs are thrown and no one is truly heard. The sabotage is to form a “User Shadow Council”—a rotating group of the actual end-users who will be most affected. They are given genuine power: a non-negotiable veto at two separate stages of development. It’s no longer a performance of listening; it’s a hostage negotiation with the people you claim to be helping.
Sabotage Tactic #3: To Counterfeit Applied Curiosity… Make the Leaders Bleed. The performance of curiosity is delegating “exploration” to a junior team. The sabotage is the “Blood in the Game” rule. Once a quarter, every leader on the executive team must personally run a small, cheap, fast experiment and present their raw, unfiltered findings. No proxies. No polished decks. They must get their own hands dirty to show that curiosity is a messy, risky practice, not a clean performance watched from a safe distance.
Sabotage Tactic #4: To Counterfeit Performance Drive… Chain the Pilot to its Scaled Twin. The performance of drive is the standing ovation for the pilot, with no second act. The sabotage is the “Scaled Twin Mandate.” No pilot program can receive funding without an accompanying, pre-approved, fully-funded scaling plan. The moment the pilot meets its success criteria, that scaling plan is automatically triggered. The pilot is no longer the show; it’s just the fuse on the rocket.
Sabotage Tactic #5: To Counterfeit Ethical Stewardship… Unleash the Red Team. The performance of ethics is a PR clean-up operation. The sabotage is to fund an independent, internal “Red Team” from day one. Their sole purpose is to be a hostile attacker. Their job is to find and publicly expose the project’s ethical flaws and biases. Their success is measured by how much damage they can do to the project before it ever sees the light of day. This makes ethics a core part of the design, not the apology tour.
These tactics are dangerous. They will be met with resistance from those who are comfortable in the theater. But the real horror isn’t failing. The real horror is succeeding at a performance that never mattered, while the world outside the theatre walls moved on without you. The set is just wood and canvas. It’s time to start tearing it down.
The lights are dim. In the sterile conference room, under the low hum of the servers, the show is about to begin. This isn’t Broadway. This is the “pilot theater,” the grand stage where innovation is performed, not delivered. We see the impressive demos, the slick dashboards, the confident talk of transformation. It’s a magnificent production. But pull back the curtain, and you’ll find him: a nervous man, bathed in the glow of a monitor, frantically pulling levers. He’s following a script, a framework, a process so perfectly executed that everyone has forgotten to ask if the city of Oz he’s projecting is even real.
The data, when you can find it in the dark, is grim. A staggering 95% of generative AI programs fail to deliver any real value. The stage is littered with the ghosts of failed pilots. We’ve become so obsessed with the performance of progress that we’ve forgotten the point of it. The man behind the curtain is a master of Agile ceremonies, his stand-ups are flawless, his retrospectives insightful. He can tell you, with perfect clarity, that the team followed the process beautifully. But when you ask him what they were supposed to be delivering, his eyes go blank. The script didn’t mention that part.
And now, a new script has arrived. It has a name, of course. They always do. This one is called SHAPE.
The New Framework Stares Back
The SHAPE index was born from the wreckage of that 95%. It’s a framework meant to identify the five key behaviors of leaders who can actually escape the theater and build something real. It’s supposed to be our map out of Oz. But in a world that worships the map over the destination, we must ask: Is this a tool for the leader, or is the leader just becoming a better-trained tool for the framework? Is this a way out, or just a more elaborate set of levers to pull?
Let’s look at the five acts of this new play.
Act I: Strategic Agility
The script says a leader must plan for the long term while pivoting in the short term. In the theater, this is a beautiful piece of choreography. The leader stands at the whiteboard, decisively moving charts around, declaring a “pivot.” It looks like genius. It feels like action. But too often, it’s just rearranging the props on stage. The underlying set—the core business problem—remains unchanged. The applause is for the performance of agility, not the achievement of a better position.
Act II: Human Centricity
Here, the actor-leader must perform empathy. They must quell the rising anxiety of the workforce. The mantra, repeated with a fixed smile, is: “AI will make humans better.” It sounds reassuring, but the chill remains. The change is designed in closed rooms and rolled out from the top down. Psychological safety isn’t a culture; it’s a talking point in a town hall. The goal isn’t to build trust, but to manage dissent just enough to keep the show from being cancelled.
Act III: Applied Curiosity
This act requires the leader to separate signal from the deafening hype. So, the theater puts on a dazzling display of “disciplined experimentation.” New, shiny AI toys are paraded across the stage. Each pilot has a clear learning objective, a report is dutifully filed, and then… nothing. The learning isn’t applied; it’s archived. The point was never to learn; it was to be seen learning. The experiments are just another scene, designed to convince the audience that something, anything, is happening.
Act IV: Performance Drive
This is where the term “pilot theater” comes directly from the script. The curtain falls on the pilot, and the applause is thunderous. Success is declared. But when you ask what happens next, how it scales, how it delivers that fabled ROI, you’re met with silence. The cast is already rehearsing for the next pilot, the next opening night. Success is measured in the activity of the performance, not the revenue at the box office. The show is celebrated, but the business quietly bleeds.
Act V: Ethical Stewardship
The final, haunting act. This part of the script is often left on the floor, only picked up when a crisis erupts. A reporter calls. A dataset is found to be biased. Suddenly, the theater puts on a frantic, ad-libbed performance of responsibility. Governance is bolted on like a cheap prop. It’s an afterthought, a desperate attempt to manage the fallout after the curtain has been torn down and the audience sees the wizard for what he is: just a man, following a script that was fundamentally flawed from the start.
Are We the Shapers, or Are We Being Shaped?
The good news, the researchers tell us, is that these five SHAPE capabilities can be taught. It’s a comforting thought. But in the eerie glow of the pilot theater, a darker question emerges: Are we teaching leaders to be effective, or are we just teaching them to be better actors?
We’ve been here before with Agile, with Six Sigma, with every framework that promised a revolution and instead delivered a new form of ritual. We perfect the process and forget the purpose. We fall in love with the intricate levers and the booming voice they produce, and we never step out from behind the curtain to see if anyone is even listening anymore.
The SHAPE index gives us a language to describe the leaders we need. But it also gives us a new, more sophisticated script to hide behind. And as we stand here, in the perpetual twilight of the pilot theater, the most important question isn’t whether our leaders have SHAPE. It’s whether we are the shapers, or if we are merely, and quietly, being shaped.
An Introduction to a New Paradigm in AI Assessment
As the complexity and ubiquity of artificial intelligence models, particularly Large Language Models (LLMs), continue to grow, the need for robust, scalable, and nuanced evaluation frameworks has become paramount. Traditional evaluation methods, often relying on statistical metrics or limited human review, are increasingly insufficient for assessing the qualitative aspects of modern AI outputs—such as helpfulness, empathy, cultural appropriateness, and creative coherence. This challenge has given rise to an innovative paradigm: using LLMs themselves as “judges” to evaluate the outputs of other models. This approach, often referred to as LLM-as-a-Judge, represents a significant leap forward, offering a scalable and sophisticated alternative to conventional methods.
Traditional evaluation is fraught with limitations. Manual human assessment, while providing invaluable insight, is notoriously slow and expensive. It is susceptible to confounding factors, inherent biases, and can only ever cover a fraction of the vast output space, missing a significant number of factual errors. These shortcomings can lead to harmful feedback loops that impede model improvement. In contrast, the LLM-as-a-Judge approach provides a suite of compelling advantages:
Scalability: An LLM judge can evaluate millions of outputs with a speed and consistency that no human team could ever match.
Complex Understanding: LLMs possess a deep semantic and contextual understanding, allowing them to assess nuances that are beyond the scope of simple statistical metrics.
Cost-Effectiveness: Once a judging model is selected and configured, the cost per evaluation is a tiny fraction of a human’s time.
Flexibility: The evaluation criteria can be adjusted on the fly with a simple change in the prompt, allowing for rapid iteration and adaptation to new tasks.
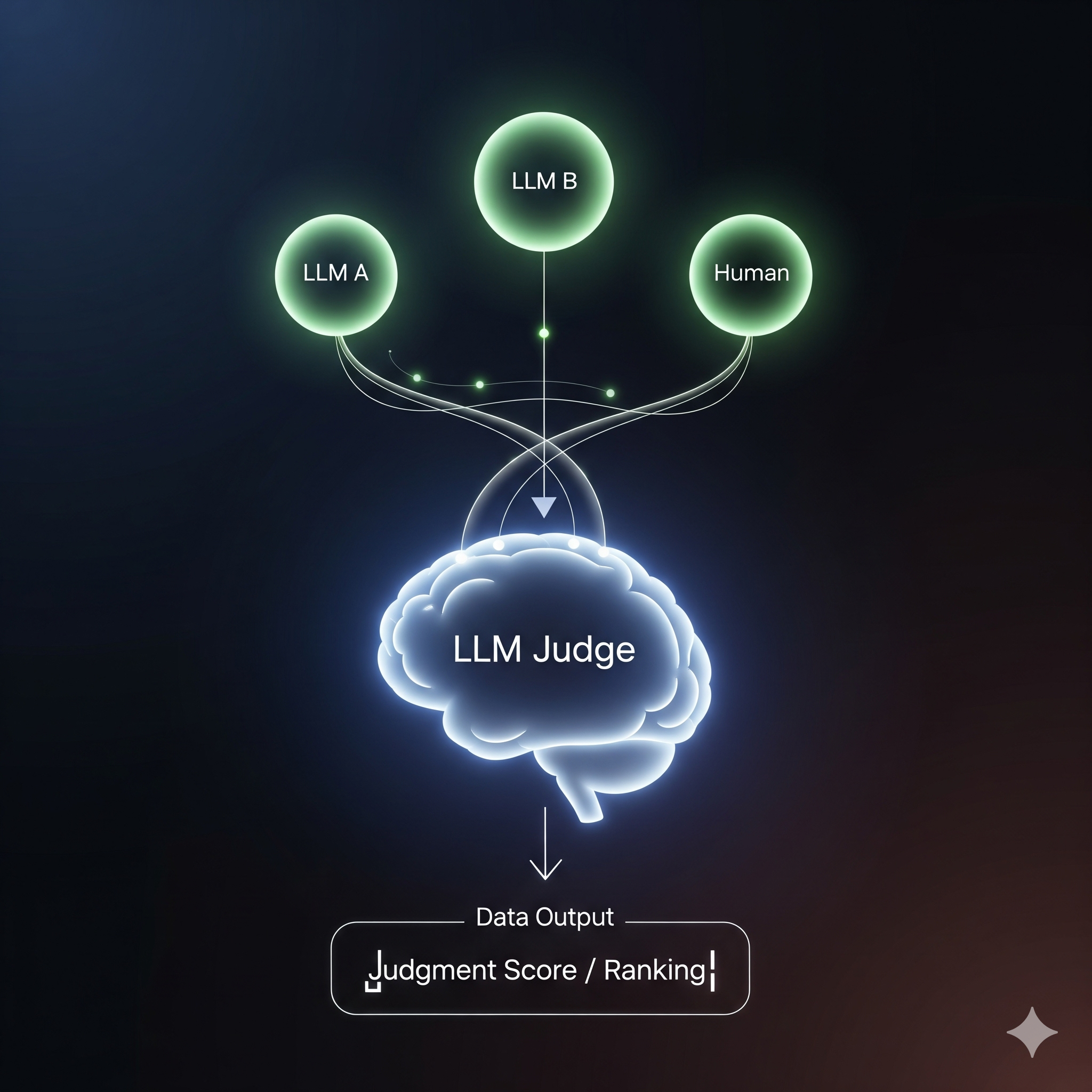
There are several scoring approaches to consider when implementing an LLM-as-a-Judge system. Single output scoring assesses one response in isolation, either with or without a reference answer. The most powerful method, however, is pairwise comparison, which presents two outputs side-by-side and asks the judge to determine which is superior. This method, which most closely mirrors the process of a human reviewer, has proven to be particularly effective in minimizing bias and producing highly reliable results.
When is it appropriate to use LLM-as-a-Judge? This approach is best suited for tasks requiring a high degree of qualitative assessment, such as summarization, creative writing, or conversational AI. It is an indispensable tool for a comprehensive evaluation framework, complementing rather than replacing traditional metrics.
Challenges With LLM Evaluation Techniques
While immensely powerful, the LLM-as-a-Judge paradigm is not without its own set of challenges, most notably the introduction of subtle, yet impactful, evaluation biases. A clear understanding and mitigation of these biases is critical for ensuring the integrity of the assessment process.
Nepotism Bias: The tendency of an LLM judge to favor content generated by a model from the same family or architecture.
Verbosity Bias: The mistaken assumption that a longer, more verbose answer is inherently better or more comprehensive.
Authority Bias: Granting undue credibility to an answer that cites a seemingly authoritative but unverified source.
Positional Bias: A common bias in pairwise comparison where the judge consistently favors the first or last response in the sequence.
Beauty Bias: Prioritizing outputs that are well-formatted, aesthetically pleasing, or contain engaging prose over those that are factually accurate but presented plainly.
Attention Bias: A judge’s focus on the beginning and end of a lengthy response, leading it to miss critical information or errors in the middle.
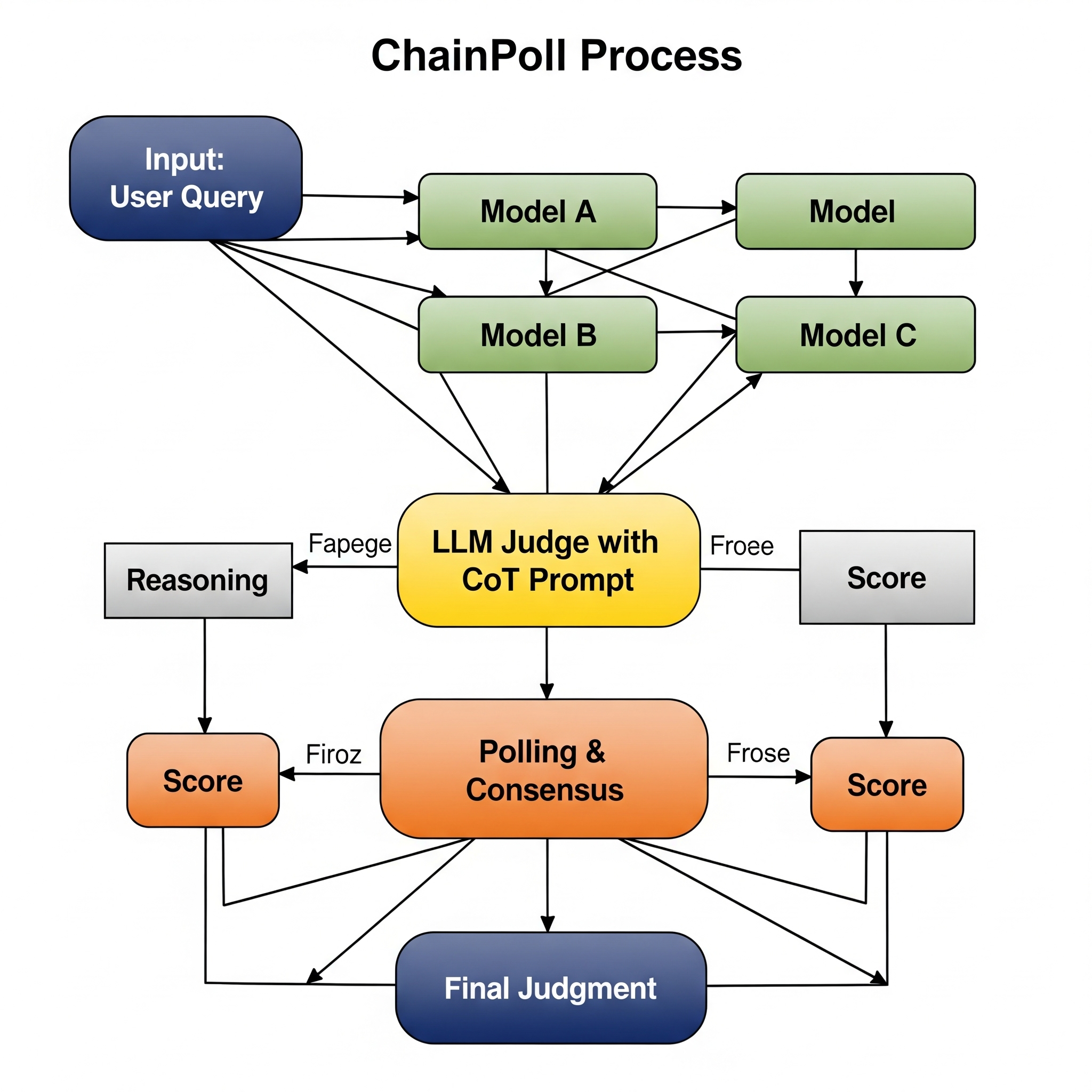
To combat these pitfalls, researchers at Galileo have developed the “ChainPoll” approach. This method marries the power of Chain-of-Thought (CoT) prompting—where the judge is instructed to reason through its decision-making process—with a polling mechanism that presents the same query to multiple LLMs. By combining reasoning with a consensus mechanism, ChainPoll provides a more robust and nuanced assessment, ensuring a judgment is not based on a single, potentially biased, point of view.
A real-world case study at LinkedIn demonstrated the effectiveness of this approach. By using an LLM-as-a-Judge system with ChainPoll, they were able to automate a significant portion of their content quality evaluations, achieving over 90% agreement with human raters at a fraction of the time and cost.
Small Language Models as Judges
While larger models like Google’s Gemini 2.5 are the gold standard for complex, nuanced evaluations, the role of specialised Small Language Models (SLMs) is rapidly gaining traction. SLMs are smaller, more focused models that are fine-tuned for a specific evaluation task, offering several key advantages over their larger counterparts.
Enhanced Focus: An SLM trained exclusively on a narrow evaluation task can often outperform a general-purpose LLM on that specific metric.
Deployment Flexibility: Their small size makes them ideal for on-device or edge deployment, enabling real-time, low-latency evaluation.
Production Readiness: SLMs are more stable, predictable, and easier to integrate into production pipelines.
Cost-Efficiency: The cost per inference is significantly lower, making them highly economical for large-scale, high-frequency evaluations.
Galileo’s latest offering, Luna 2, exemplifies this trend. Luna 2 is a new generation of SLM specifically designed to provide low-latency, low-cost metric evaluations. Its architecture is optimized for speed and accuracy, making it an ideal candidate for tasks such as sentiment analysis, toxicity detection, and basic factual verification where a large, expensive LLM may be overkill.
Best Practices for Creating Your LLM-as-a-Judge
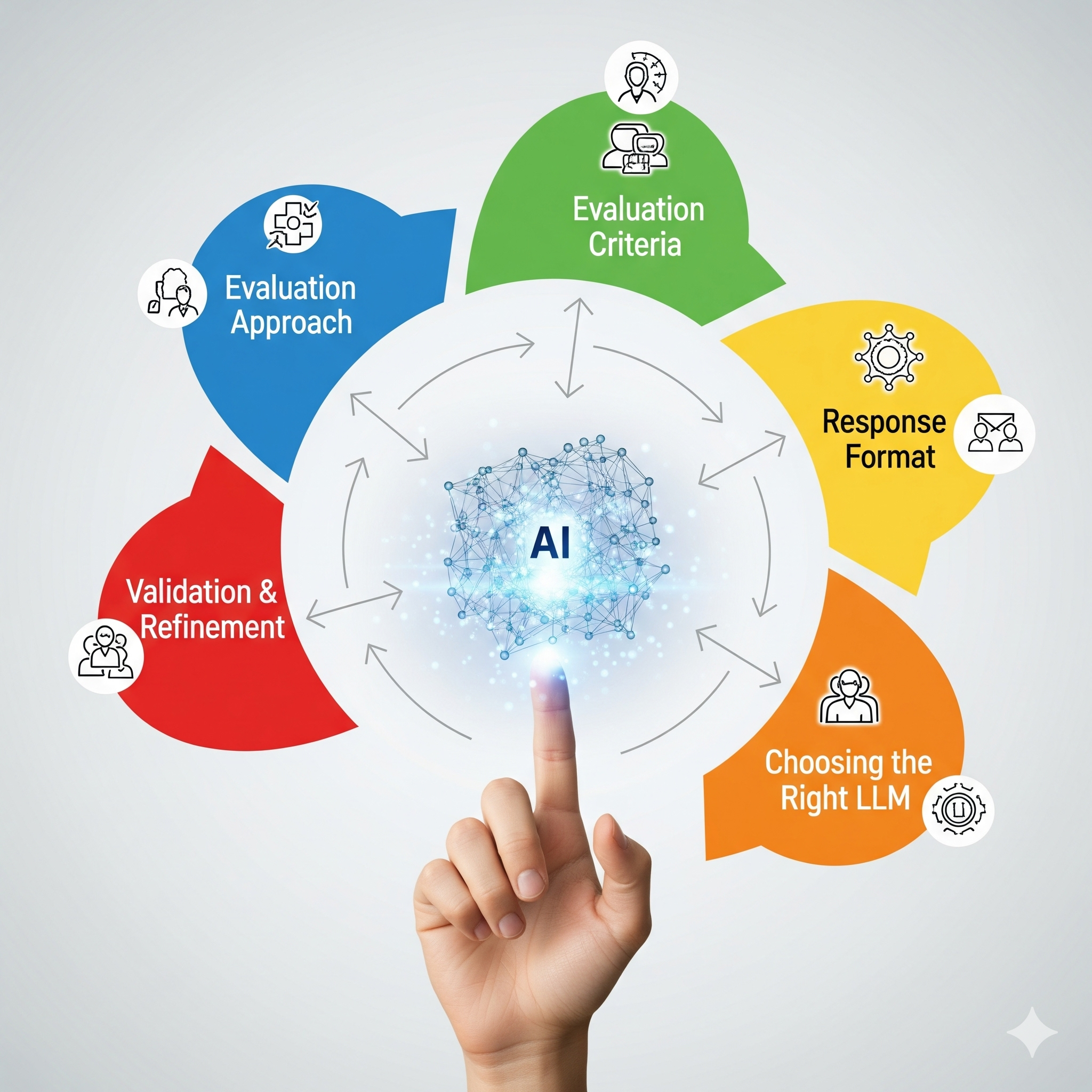
Building a reliable LLM judge is an art and a science. It requires a thoughtful approach to five key components.
Evaluation Approach: Decide whether a simple scoring system (e.g., 1-5 scale) or a more sophisticated ranking and comparison system is best. Consider a multidimensional system that evaluates on multiple criteria.
Evaluation Criteria: Clearly and precisely define the metrics you are assessing. These could include factual accuracy, clarity, adherence to context, tone, and formatting requirements. The prompt must be unambiguous.
Response Format: The judge’s output must be predictable and machine-readable. A discrete scale (e.g., 1-5) or a structured JSON output is ideal. JSON is particularly useful for multidimensional assessments.
Choosing the Right LLM: The choice of the base LLM for your judge is perhaps the most critical decision. Models must balance performance, cost, and task specificity. While smaller models like Luna 2 excel at specific tasks, a robust general-purpose model like Google’s Gemini 2.5 has proven to be exceptionally effective as a judge due to its unparalleled reasoning capabilities and broad contextual understanding.
Other Considerations: Account for bias detection, consistency (e.g., by testing the same input multiple times), edge case handling, interpretability of results, and overall scalability.
A Conceptual Code Example for a Core Judge
The following is a simplified, conceptual example of how a core LLM judge function might be configured:
def create_llm_judge_prompt(evaluation_criteria, user_query, candidate_responses):
"""
Constructs a detailed prompt for an LLM judge.
"""
prompt = f"""
You are an expert evaluator of AI responses. Your task is to judge and rank the following responses
to a user query based on the following criteria:
Criteria:
{evaluation_criteria}
User Query:
"{user_query}"
Candidate Responses:
Response A: "{candidate_responses['A']}"
Response B: "{candidate_responses['B']}"
Instructions:
1. Think step-by-step and write your reasoning.
2. Based on your reasoning, provide a final ranking of the responses.
3. Your final output must be in JSON format: {{"reasoning": "...", "ranking": {{"A": "...", "B": "..."}}}}
"""
return prompt
def validate_llm_judge(judge_function, test_data, metrics):
"""
Validates the performance of the LLM judge against a human-labeled dataset.
"""
judgements = []
for test_case in test_data:
prompt = create_llm_judge_prompt(test_case['criteria'], test_case['query'], test_case['responses'])
llm_output = judge_function(prompt) # This would be your API call to Gemini 2.5
judgements.append({
'llm_ranking': llm_output['ranking'],
'human_ranking': test_case['human_ranking']
})
# Calculate metrics like precision, recall, and Cohen's Kappa
# based on the judgements list.
return calculate_metrics(judgements, metrics)
Tricks to Improve LLM-as-a-Judge
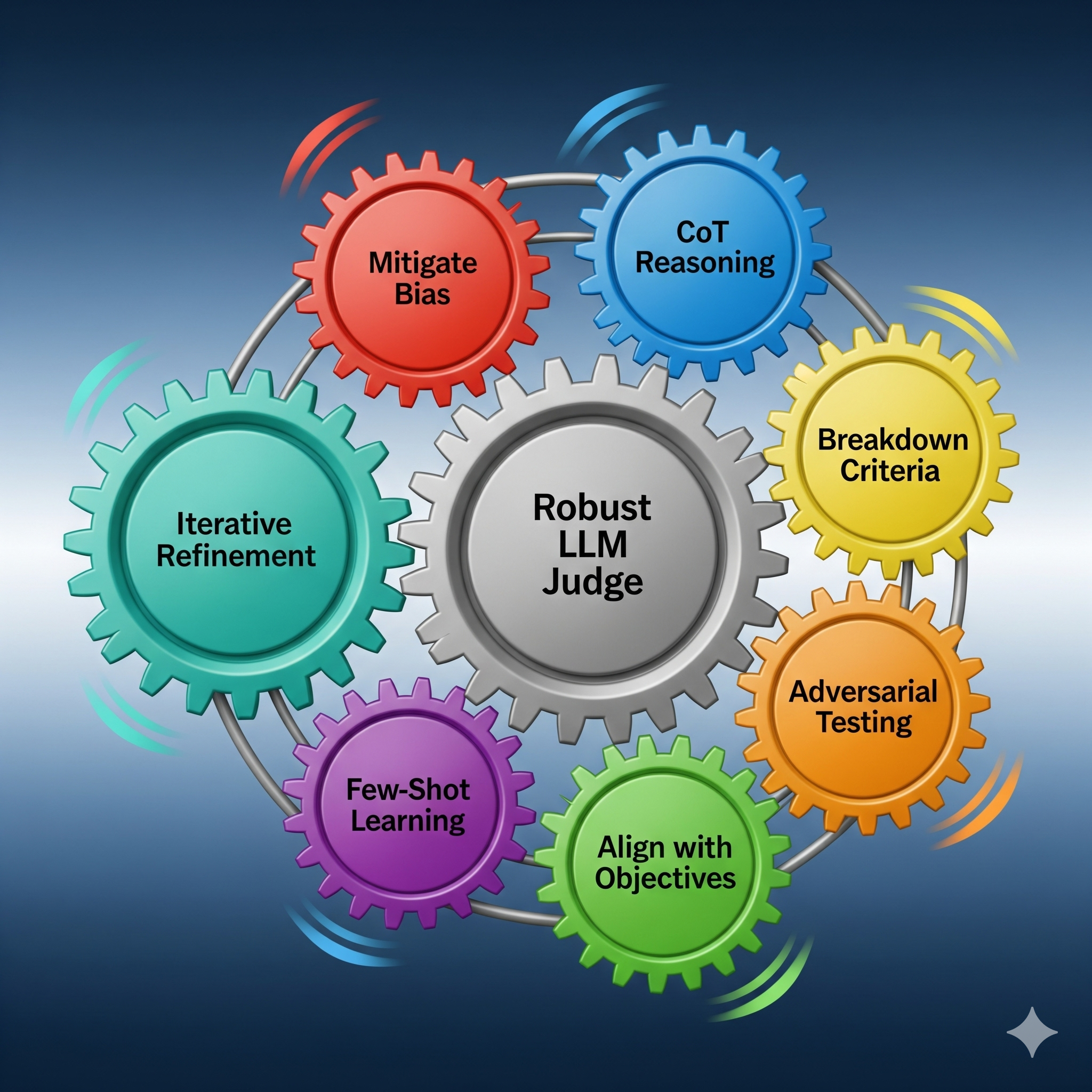
Building upon the foundational best practices, there are seven practical enhancements that can dramatically improve the reliability and consistency of your LLM judge.
Mitigate Evaluation Biases: As discussed, biases are a constant threat. Use techniques like varying the response sequence for positional bias and polling multiple LLMs to combat nepotism.
Enforce Reasoning with CoT Prompting: Always instruct your judge to “think step-by-step.” This forces the model to explain its logic, making its decisions more transparent and often more accurate.
Break Down Criteria: Instead of a single, ambiguous metric like “quality,” break it down into granular components such as “factual accuracy,” “clarity,” and “creativity.” This allows for more targeted and precise assessments.
Align with User Objectives: The LLM judge’s prompts and criteria should directly reflect what truly matters to the end user. An output that is factually correct but violates the desired tone is not a good response.
Utilise Few-Shot Learning: Providing the judge with a few well-chosen examples of good and bad responses, along with detailed explanations, can significantly improve its understanding and performance on new tasks.
Incorporate Adversarial Testing: Actively create and test with intentionally difficult or ambiguous edge cases to challenge your judge and identify its weaknesses.
Implement Iterative Refinement: Evaluation is not a one-time process. Continuously track inconsistencies, review challenging responses, and use this data to refine your prompts and criteria.
By synthesizing these strategies into a comprehensive toolbox, we can build a highly robust and reliable LLM judge. Ultimately, the effectiveness of any LLM-as-a-Judge system is contingent on the underlying model’s reasoning capabilities and its ability to handle complex, open-ended tasks. While many models can perform this function, our extensive research and testing have consistently shown that Google’s Gemini 2.5 outperforms its peers in the majority of evaluation scenarios. Its advanced reasoning and nuanced understanding of context make it the definitive choice for building an accurate, scalable, and sophisticated evaluation framework.
There is a theory which states that if ever anyone discovers exactly what the business world is for, it will instantly disappear and be replaced by something even more bizarre and inexplicable. There is another theory which states that this has already happened. This certainly goes a long way to explaining the current corporate strategy for dealing with Artificial Intelligence, which is to largely ignore it, in the same way that a startled periwinkle might ignore an oncoming bulldozer, hoping that if it doesn’t make any sudden moves the whole “unsettling” situation will simply settle down.
This is, of course, a terrible strategy, because while everyone is busy not looking, the bulldozer is not only getting closer, it’s also learning to draw a surprisingly good, yet legally dubious, cartoon mouse.
We live in an age of what is fashionably called “Agile,” a term which here seems to mean “The Art of Controlled Panic.” It’s a frantic, permanent state of trying to build the aeroplane while it’s already taxiing down the runway, fueled by lukewarm coffee and a deep-seated fear of the next quarterly review. For years, the panic-release valve was off-shoring. When a project was on fire, you could simply bundle up your barely coherent requirements and fling them over the digital fence to a team in another time zone, hoping they’d throw back a working solution before morning.
Now, we have perfected this model. AI is the new, ultimate off-shoring. The team is infinitely scalable, works for pennies, and is located somewhere so remote it isn’t even on a map. It’s in “The Cloud,” a place that is reassuringly vague and requires no knowledge of geography whatsoever.
The problem is, this new team is a bit weird. You still need that one, increasingly stressed-out human—let’s call them the Prompt Whisperer—to translate the frantic, contradictory demands of the business into a language the machine will understand. They are the new middle manager, bridging the vast, terrifying gap between human chaos and silicon logic. But there’s a new, far more alarming, item in their job description.
You see, the reason this new offshore team is so knowledgeable is because it has been trained by binge-watching the entire internet. Every film, every book, every brand logo, every cat picture, and every episode of every cartoon ever made. And as the ongoing legal spat between the Disney/Universal behemoth and the AI art platform Midjourney demonstrates, the hangover from this creative binge is about to kick in with the force of a Pan Galactic Gargle Blaster.
The issue, for any small business cheerfully using an AI to design their new logo, is one of copyright. In the US, they have a principle called “fair use,” which is a wonderfully flexible and often confusing set of rules. In the UK, we have “fair dealing,” which is a narrower, more limited set of rules that is, in its own way, just as confusing. If the difference between the two seems unclear, then congratulations, you have understood the central point perfectly: you are almost certainly in trouble.
The AI, you see, doesn’t create. It remixes. And it has no concept of ownership. Ask it to design a logo for your artisanal doughnut shop, and it might cheerfully serve up something that looks uncannily like the beloved mascot of a multi-billion-dollar entertainment conglomerate. The AI isn’t your co-conspirator; it’s the unthinking photocopier, and you’re the one left holding the legally radioactive copy. Your brilliant, cost-effective branding exercise has just become a business-ending legal event.
So, here we are, practicing the art of controlled panic on a legal minefield. The new off-shored intelligence is a powerful, dangerous, and creatively promiscuous force. That poor Prompt Whisperer isn’t just briefing the machine anymore; they are its parole officer, desperately trying to stop it from cheerfully plagiarizing its way into oblivion. The only thing that hasn’t “settled down” is the dust from the first wave of cease-and-desist letters. And they are, I assure you, on their way.