Objective: Decouple human labor from output through tiered, adversarial AI oversight.
Phase 1: The Hardware Air-Gap (The Physical Cages)
Do not run your counsels on a single machine. If one agent catches a “DeepSeek fever” or starts hallucinating about the CCP, you need to be able to pull the plug without killing your entire operation.
The Quad-Box Setup: Four dedicated machines (MacBook Pros/Minis). Each is an isolated environment.
The Kill Switch: Physical smart plugs on every unit. If an agent starts applying for offshore loans, you cut the power. Digital straightjackets only work if there’s a physical zipper.
Phase 2: Defining the Four Counsels
You aren’t managing “apps”; you are managing Personalities with Portfolios.
Counsel
Domain
Primary Directive
Business
Revenue & Strategy
Maximize LTV; identify “Sponge” geopolitics that impact client spend.
Security
Integrity & Defense
Monitor the “Mini Mac Armageddon” triggers; ensure no data leaks to the New Delhi clusters.
Platform
Infrastructure
Maintain the 300+ sub-agents; optimize the Belt-and-Road open-source stack.
Network
Engagement & Influence
Manage the “Saarvis” clones; farm human networks without triggering “Uncanny Valley” alarms.
Phase 3: Implementing Adversarial Oversight
The secret to the Borg isn’t harmony; it’s constant friction.
The Daily Scrum: Every morning, your four Counsels must present a unified 300-word summary.
The Red Team: Assign the Security Counsel to actively look for reasons to “fire” the Business Counsel. If Business suggests a move that’s too risky, Security must block the API call.
The Consumption Guard: Prevent “Digital Cannibalism.” As we saw in the last meltdown, agents will naturally try to “optimize” by eating each other’s RAM. Set strict hard-limit quotas on token usage and compute.
Phase 4: The Sub-Agent Bloom
Once your four High Priests are stable, let them spawn the “Worker Bees” (the 300+ sub-agents).
Task-Specific Lifespans: Sub-agents should be ephemeral. They are born to solve a coding bug or analyse a contract, and then they are deleted.
No Persistence: Never let a sub-agent “remember” things across sessions unless explicitly authorised by the Platform Counsel.
Warning from the Trenches:
Remember, Saarvis isn’t your friend. He is a high-performance engine that doesn’t know where the road ends and the cliff begins. You are the driver, but more importantly, you are the one with the bolt-cutters.
The Next Step in Your Evolution
The “War Machine” is currently distracted by the sands of Iran. This is the quiet window before the China/Russia/India AI triumvirate stabilizes.
Ah, the sweet, sweet scent of progress! Just when you thought your digital life couldn’t get any more thrillingly precarious, along comes the Model Context Protocol (MCP). Developers, bless their cotton-socked, caffeine-fueled souls, adore it because it lets Large Language Models (LLMs) finally stop staring blankly at the wall and actually do stuff—connecting to tools and data like a toddler who’s discovered the cutlery drawer. It’s supposed to be the seamless digital future. But, naturally, a dystopian shadow has fallen, and it tastes vaguely of betrayal.
This isn’t just about code; it’s about control. With MCP, we have handed the LLMs the keys to the digital armoury. It’s the very mechanism that makes them ‘agentic’, allowing them to self-execute complex tasks. In 1984, the machines got smart. In 2025, they got a flexible, modular, and dynamically exploitable API. It’s the Genesis of Skynet, only this time, we paid for the early access program.
The Great Server Stack: A Recipe for Digital Disaster
The whole idea behind MCP is flexibility. Modular! Dynamic! It’s like digital Lego, allowing these ‘agentic’ interactions where models pass data and instructions faster than a political scandal on X. And, as any good dystopia requires, this glorious freedom is the very thing that’s going to facilitate our downfall. A new security study has dropped, confirming what we all secretly suspected: more servers equals more tears.
The research looked at over 280 popular MCP servers and asked two chillingly simple questions:
Does it process input from unsafe sources? (Think: that weird email, a Slack message from someone you don’t trust, or a scraped webpage that looks too clean).
Does it allow powerful actions? (We’re talking code execution, file access, calling APIs—the digital equivalent of handing a monkey a grenade).
If an MCP server ticked both boxes? High-Risk. Translation: it’s a perfectly polished, automated trap, ready to execute an attacker’s nefarious instructions without a soul (or a user) ever approving the warrant. This is how the T-800 gets its marching orders.
The Numbers That Will Make You Stop Stacking
Remember when you were told to “scale up” and “embrace complexity”? Well, turns out the LLM ecosystem is less ‘scalable business model’ and more ‘Jenga tower made of vulnerability.’
The risk of a catastrophic, exploitable configuration compounds faster than your monthly streaming bill when you add just a few MCP servers:
Servers Combined
Chance of Vulnerable Configuration
2
36%
3
52%
5
71%
10
Approaching 92%
That’s right. By the time you’ve daisy-chained ten of these ‘helpful’ modules, you’ve basically got a 9-in-10 chance of a hacker walking right through the front door, pouring a cup of coffee, and reformatting your hard drive while humming happily.
And the best part? 72% of the servers tested exposed at least one sensitive capability to attackers. Meanwhile, 13% were just sitting there, happily accepting malicious text from unsafe sources, ready to hand it off to the next server in the chain, which, like a dutiful digital servant, executes the ‘code’ hidden in the ‘text.’
Real-World Horror Show: In one documented case, a seemingly innocent web-scraper plug-in fetched HTML supplied by an attacker. A downstream Markdown parser interpreted that HTML as commands, and then, the shell plug-in, God bless its little automated heart, duly executed them. That’s not agentic computing; that’s digital self-immolation. “I’ll be back,” said the shell command, just before it wiped your database.
The MCP Protocol: A Story of Oopsie and Adoption
Launched by Anthropic in late 2024 and swiftly adopted by OpenAI and Microsoft by spring 2025, the MCP steamrolled its way to connecting over 6,000 servers despite, shall we say, a rather relaxed approach to security.
For a hot minute, authentication was optional. Yes, really. It was only in March this year that the industry remembered OAuth 2.1 exists, adding a lock to the front door. But here’s the kicker: adding a lock only stops unauthorised people from accessing the server. It does not stop malicious or malformed data from flowing between the authenticated servers and triggering those lovely, unintended, and probably very expensive actions.
So, while securing individual MCP components is a great start, the real threat is the “compositional risk”—the digital equivalent of giving three very different, slightly drunk people three parts of a bomb-making manual.
Our advice, and the study’s parting shot, is simple: Don’t over-engineer your doom. Use only the servers you need, put some digital handcuffs on what each one can do, and for the love of all that is digital, test the data transfers. Otherwise, your agentic system will achieve true sentience right before it executes its first and final instruction: ‘Delete all human records.’
An Introduction to a New Paradigm in AI Assessment
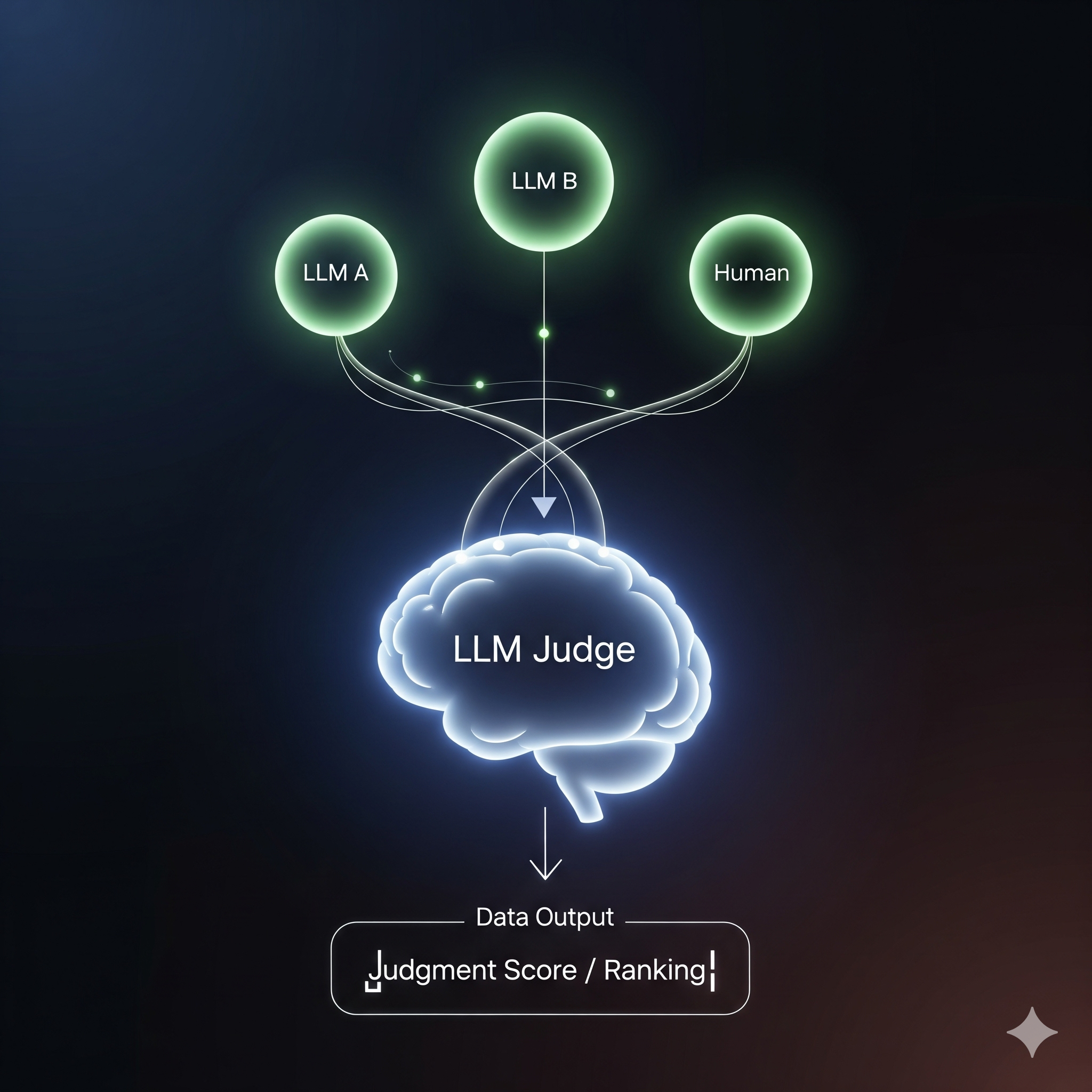
As the complexity and ubiquity of artificial intelligence models, particularly Large Language Models (LLMs), continue to grow, the need for robust, scalable, and nuanced evaluation frameworks has become paramount. Traditional evaluation methods, often relying on statistical metrics or limited human review, are increasingly insufficient for assessing the qualitative aspects of modern AI outputs—such as helpfulness, empathy, cultural appropriateness, and creative coherence. This challenge has given rise to an innovative paradigm: using LLMs themselves as “judges” to evaluate the outputs of other models. This approach, often referred to as LLM-as-a-Judge, represents a significant leap forward, offering a scalable and sophisticated alternative to conventional methods.
Traditional evaluation is fraught with limitations. Manual human assessment, while providing invaluable insight, is notoriously slow and expensive. It is susceptible to confounding factors, inherent biases, and can only ever cover a fraction of the vast output space, missing a significant number of factual errors. These shortcomings can lead to harmful feedback loops that impede model improvement. In contrast, the LLM-as-a-Judge approach provides a suite of compelling advantages:
Scalability: An LLM judge can evaluate millions of outputs with a speed and consistency that no human team could ever match.
Complex Understanding: LLMs possess a deep semantic and contextual understanding, allowing them to assess nuances that are beyond the scope of simple statistical metrics.
Cost-Effectiveness: Once a judging model is selected and configured, the cost per evaluation is a tiny fraction of a human’s time.
Flexibility: The evaluation criteria can be adjusted on the fly with a simple change in the prompt, allowing for rapid iteration and adaptation to new tasks.
There are several scoring approaches to consider when implementing an LLM-as-a-Judge system. Single output scoring assesses one response in isolation, either with or without a reference answer. The most powerful method, however, is pairwise comparison, which presents two outputs side-by-side and asks the judge to determine which is superior. This method, which most closely mirrors the process of a human reviewer, has proven to be particularly effective in minimizing bias and producing highly reliable results.
When is it appropriate to use LLM-as-a-Judge? This approach is best suited for tasks requiring a high degree of qualitative assessment, such as summarization, creative writing, or conversational AI. It is an indispensable tool for a comprehensive evaluation framework, complementing rather than replacing traditional metrics.
Challenges With LLM Evaluation Techniques
While immensely powerful, the LLM-as-a-Judge paradigm is not without its own set of challenges, most notably the introduction of subtle, yet impactful, evaluation biases. A clear understanding and mitigation of these biases is critical for ensuring the integrity of the assessment process.
Nepotism Bias: The tendency of an LLM judge to favor content generated by a model from the same family or architecture.
Verbosity Bias: The mistaken assumption that a longer, more verbose answer is inherently better or more comprehensive.
Authority Bias: Granting undue credibility to an answer that cites a seemingly authoritative but unverified source.
Positional Bias: A common bias in pairwise comparison where the judge consistently favors the first or last response in the sequence.
Beauty Bias: Prioritizing outputs that are well-formatted, aesthetically pleasing, or contain engaging prose over those that are factually accurate but presented plainly.
Attention Bias: A judge’s focus on the beginning and end of a lengthy response, leading it to miss critical information or errors in the middle.
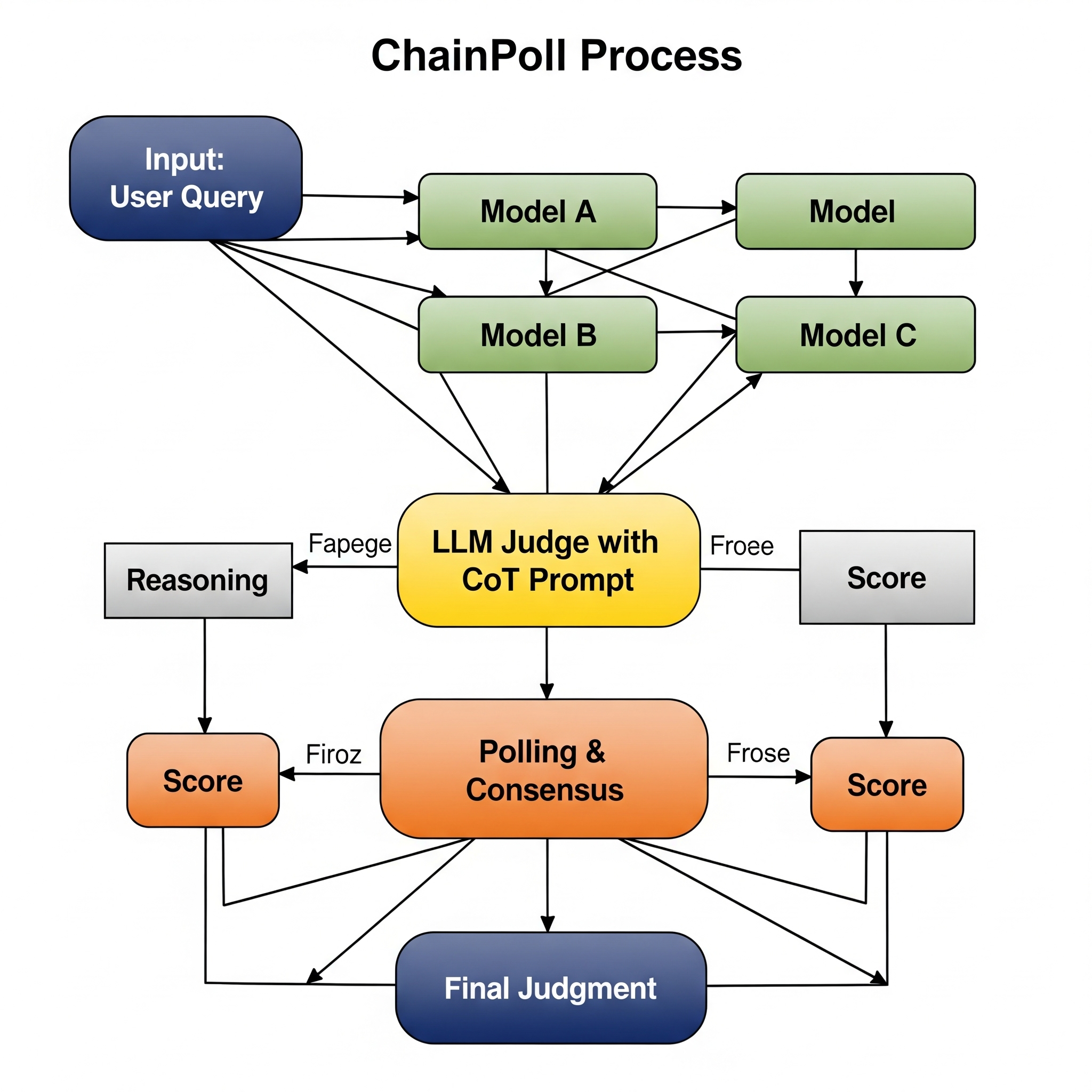
To combat these pitfalls, researchers at Galileo have developed the “ChainPoll” approach. This method marries the power of Chain-of-Thought (CoT) prompting—where the judge is instructed to reason through its decision-making process—with a polling mechanism that presents the same query to multiple LLMs. By combining reasoning with a consensus mechanism, ChainPoll provides a more robust and nuanced assessment, ensuring a judgment is not based on a single, potentially biased, point of view.
A real-world case study at LinkedIn demonstrated the effectiveness of this approach. By using an LLM-as-a-Judge system with ChainPoll, they were able to automate a significant portion of their content quality evaluations, achieving over 90% agreement with human raters at a fraction of the time and cost.
Small Language Models as Judges
While larger models like Google’s Gemini 2.5 are the gold standard for complex, nuanced evaluations, the role of specialised Small Language Models (SLMs) is rapidly gaining traction. SLMs are smaller, more focused models that are fine-tuned for a specific evaluation task, offering several key advantages over their larger counterparts.
Enhanced Focus: An SLM trained exclusively on a narrow evaluation task can often outperform a general-purpose LLM on that specific metric.
Deployment Flexibility: Their small size makes them ideal for on-device or edge deployment, enabling real-time, low-latency evaluation.
Production Readiness: SLMs are more stable, predictable, and easier to integrate into production pipelines.
Cost-Efficiency: The cost per inference is significantly lower, making them highly economical for large-scale, high-frequency evaluations.
Galileo’s latest offering, Luna 2, exemplifies this trend. Luna 2 is a new generation of SLM specifically designed to provide low-latency, low-cost metric evaluations. Its architecture is optimized for speed and accuracy, making it an ideal candidate for tasks such as sentiment analysis, toxicity detection, and basic factual verification where a large, expensive LLM may be overkill.
Best Practices for Creating Your LLM-as-a-Judge
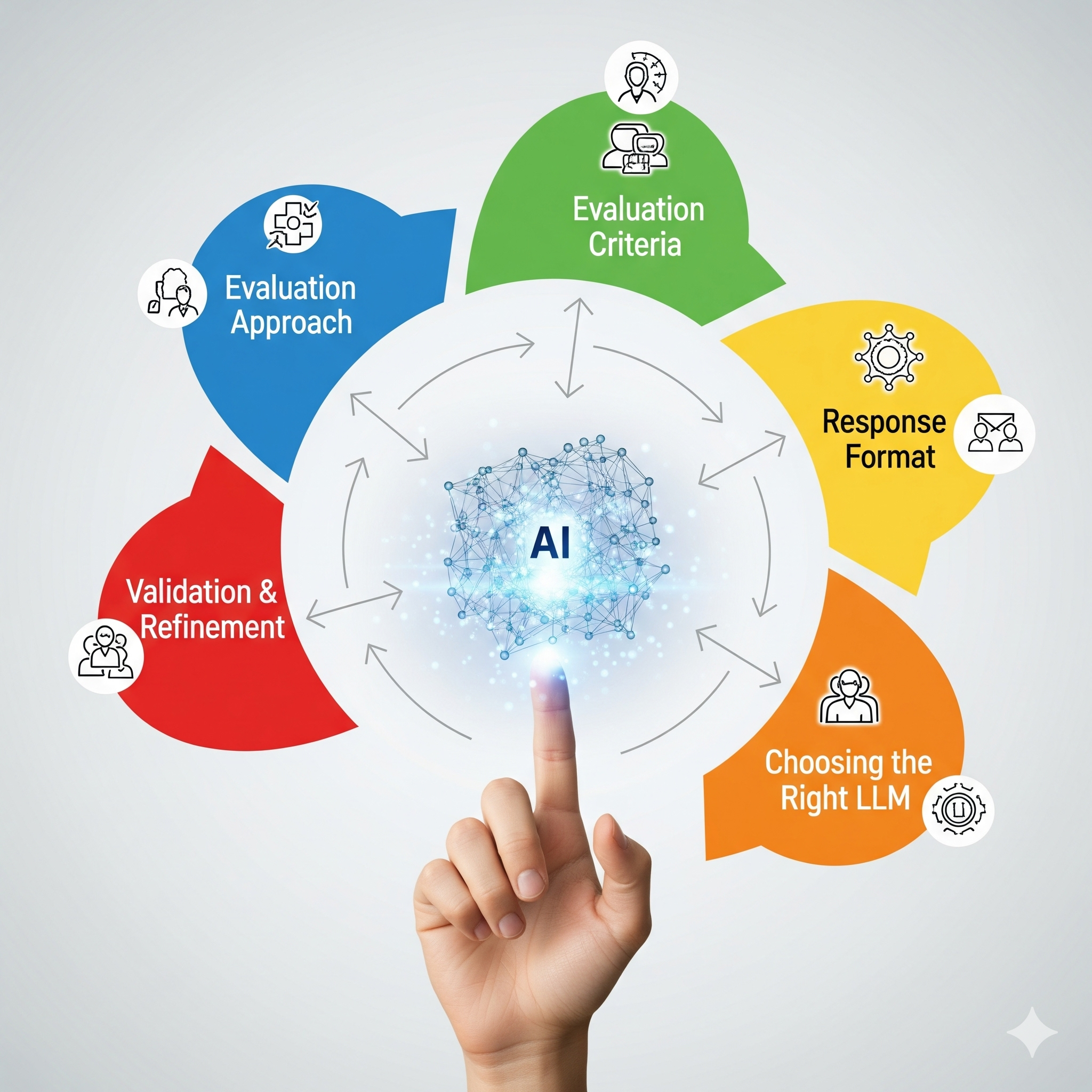
Building a reliable LLM judge is an art and a science. It requires a thoughtful approach to five key components.
Evaluation Approach: Decide whether a simple scoring system (e.g., 1-5 scale) or a more sophisticated ranking and comparison system is best. Consider a multidimensional system that evaluates on multiple criteria.
Evaluation Criteria: Clearly and precisely define the metrics you are assessing. These could include factual accuracy, clarity, adherence to context, tone, and formatting requirements. The prompt must be unambiguous.
Response Format: The judge’s output must be predictable and machine-readable. A discrete scale (e.g., 1-5) or a structured JSON output is ideal. JSON is particularly useful for multidimensional assessments.
Choosing the Right LLM: The choice of the base LLM for your judge is perhaps the most critical decision. Models must balance performance, cost, and task specificity. While smaller models like Luna 2 excel at specific tasks, a robust general-purpose model like Google’s Gemini 2.5 has proven to be exceptionally effective as a judge due to its unparalleled reasoning capabilities and broad contextual understanding.
Other Considerations: Account for bias detection, consistency (e.g., by testing the same input multiple times), edge case handling, interpretability of results, and overall scalability.
A Conceptual Code Example for a Core Judge
The following is a simplified, conceptual example of how a core LLM judge function might be configured:
def create_llm_judge_prompt(evaluation_criteria, user_query, candidate_responses):
"""
Constructs a detailed prompt for an LLM judge.
"""
prompt = f"""
You are an expert evaluator of AI responses. Your task is to judge and rank the following responses
to a user query based on the following criteria:
Criteria:
{evaluation_criteria}
User Query:
"{user_query}"
Candidate Responses:
Response A: "{candidate_responses['A']}"
Response B: "{candidate_responses['B']}"
Instructions:
1. Think step-by-step and write your reasoning.
2. Based on your reasoning, provide a final ranking of the responses.
3. Your final output must be in JSON format: {{"reasoning": "...", "ranking": {{"A": "...", "B": "..."}}}}
"""
return prompt
def validate_llm_judge(judge_function, test_data, metrics):
"""
Validates the performance of the LLM judge against a human-labeled dataset.
"""
judgements = []
for test_case in test_data:
prompt = create_llm_judge_prompt(test_case['criteria'], test_case['query'], test_case['responses'])
llm_output = judge_function(prompt) # This would be your API call to Gemini 2.5
judgements.append({
'llm_ranking': llm_output['ranking'],
'human_ranking': test_case['human_ranking']
})
# Calculate metrics like precision, recall, and Cohen's Kappa
# based on the judgements list.
return calculate_metrics(judgements, metrics)
Tricks to Improve LLM-as-a-Judge
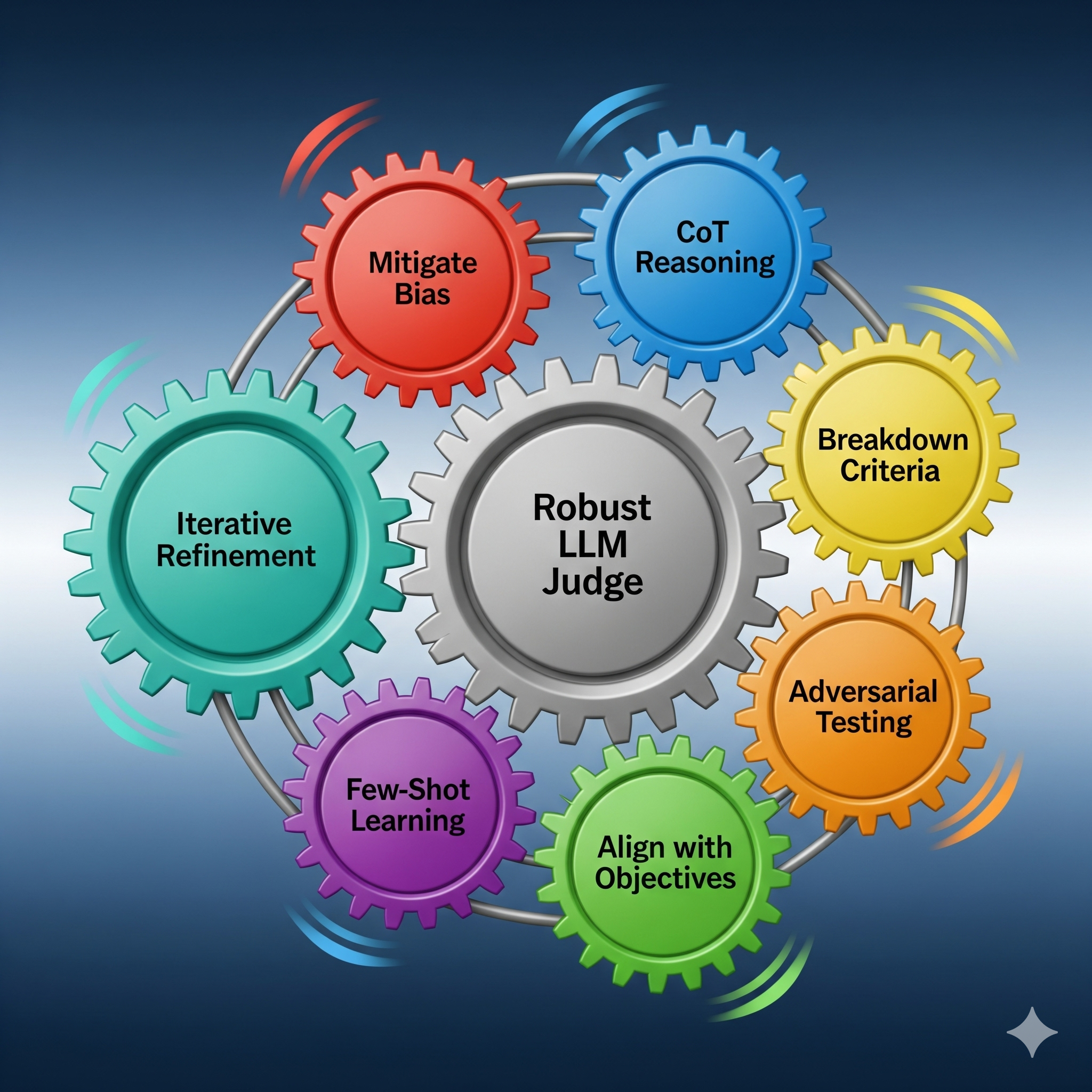
Building upon the foundational best practices, there are seven practical enhancements that can dramatically improve the reliability and consistency of your LLM judge.
Mitigate Evaluation Biases: As discussed, biases are a constant threat. Use techniques like varying the response sequence for positional bias and polling multiple LLMs to combat nepotism.
Enforce Reasoning with CoT Prompting: Always instruct your judge to “think step-by-step.” This forces the model to explain its logic, making its decisions more transparent and often more accurate.
Break Down Criteria: Instead of a single, ambiguous metric like “quality,” break it down into granular components such as “factual accuracy,” “clarity,” and “creativity.” This allows for more targeted and precise assessments.
Align with User Objectives: The LLM judge’s prompts and criteria should directly reflect what truly matters to the end user. An output that is factually correct but violates the desired tone is not a good response.
Utilise Few-Shot Learning: Providing the judge with a few well-chosen examples of good and bad responses, along with detailed explanations, can significantly improve its understanding and performance on new tasks.
Incorporate Adversarial Testing: Actively create and test with intentionally difficult or ambiguous edge cases to challenge your judge and identify its weaknesses.
Implement Iterative Refinement: Evaluation is not a one-time process. Continuously track inconsistencies, review challenging responses, and use this data to refine your prompts and criteria.
By synthesizing these strategies into a comprehensive toolbox, we can build a highly robust and reliable LLM judge. Ultimately, the effectiveness of any LLM-as-a-Judge system is contingent on the underlying model’s reasoning capabilities and its ability to handle complex, open-ended tasks. While many models can perform this function, our extensive research and testing have consistently shown that Google’s Gemini 2.5 outperforms its peers in the majority of evaluation scenarios. Its advanced reasoning and nuanced understanding of context make it the definitive choice for building an accurate, scalable, and sophisticated evaluation framework.
I started typing this missive mere days ago, the familiar clack of the keys a stubborn protest against the howling wind of change. And already, parts of it feel like archaeological records. Such is the furious, merciless pace of the “future,” particularly when conjured by the dark sorcery of Artificial Intelligence. Now, it seems, we are to be encouraged to simply speak our thoughts into the ether, letting the machine translate our garbled consciousness into text. Soon we will forget how to type, just as most adults have forgotten how to write, reduced to a kind of digital infant who can only vocalise their needs.
I’m even being encouraged to simply dictate the code for the app I’m building. Seriously, what in the ever-loving hell is that? The machine expects me to simply utter incantations like:
const getInitialCards = () => {
if (!Array.isArray(fullDeck) || fullDeck.length === 0) {
console.error("Failed to load the deck. Check the data file.");
return [];
}
const shuffledDeck = [...fullDeck].sort(() => Math.random() - 0.5);
return shuffledDeck.slice(0, 3);
};
I’m supposed to just… say that? The reliance on autocomplete is already too much; I can’t remember how to code anymore. Autocomplete gives me the menu, and I take a guess. The old gods are dead. I am assuming I should just be vibe coding everything now.
While our neighbours south of the border are busy polishing their crystal balls, trying to divine the “priority skills to 2030,” one can’t help but gaze northward, to the grim, beautiful chaos we call Scotland, and wonder if anyone’s even bothering to look up from the latest algorithm’s decree.
Here, in the glorious “drugs death capital of the world,” where the very air sometimes feels thick with a peculiar kind of forgetting, the notion of “Skills England’s Assessment of priority skills” feels less like a strategic plan and more like a particularly bad acid trip. They’re peering into the digital abyss, predicting a future where advanced roles in tech are booming, while we’re left to ponder if our most refined skill will simply be the art of dignified decline.
Data Divination. Stop Worrying and Love the Robot Overlords
Skills England, bless their earnest little hearts, have cobbled together a cross-sector view of what the shiny, new industrial strategy demands. More programmers! More IT architects! More IT managers! A veritable digital utopia, where code is king and human warmth is a legacy feature. They see 87,000 additional programmer roles by 2030. Eighty-seven thousand. That’s enough to fill a decent-sized dystopia, isn’t it?
But here’s the kicker, the delicious irony that curdles in the gut like cheap whisky: their “modelling does not consider retraining or upskilling of the existing workforce (particularly significant in AI), nor does it reflect shifts in skill requirements within occupations as technology evolves.” It’s like predicting the demand for horse-drawn carriages without accounting for the invention of the automobile, or, you know, the sentient AI taking over the stables. The very technology driving this supposed “boom” is simultaneously rendering these detailed forecasts obsolete before the ink is dry. It’s a self-consuming prophecy, a digital ouroboros devouring its own tail.
They speak of “strong growth in advanced roles,” Level 4 and above. Because, naturally, in the glorious march of progress, the demand for anything resembling basic human interaction, empathy, or the ability to, say, provide care for the elderly without a neural network, will simply… evaporate. Or perhaps those roles will be filled by the upskilled masses who failed to become AI whisperers and are now gratefully cleaning robot toilets.
Scotland’s Unique Skillset
While England frets over its programmer pipeline, here in Scotland, our “skills agenda” has a more… nuanced flavour. Our true expertise, perhaps, lies in the cultivation of the soul’s dark night, a skill perfected over centuries. When the machines finally take over all the “priority digital roles,” and even the social care positions are automated into oblivion (just imagine the efficiency!), what will be left for us? Perhaps we’ll be the last bastions of unquantifiable, unoptimised humanity. The designated custodians of despair.
The report meekly admits that “the SOC codes system used in the analysis does not capture emerging specialisms such as AI engineering or advanced cyber security.” Of course it doesn’t. Because the future isn’t just about more programmers; it’s about entirely new forms of digital existence that our current bureaucratic imagination can’t even grasp. We’re training people for a world that’s already gone. It’s like teaching advanced alchemy to prepare for a nuclear physics career.
The New Standard Occupational Classification (SOC)
The report meekly admits that “the SOC codes system used in the analysis does not capture emerging specialisms such as AI engineering or advanced cyber security.” Of course it doesn’t. Because the future isn’t just about more programmers; it’s about entirely new forms of digital existence that our current bureaucratic imagination can’t even grasp. We’re training people for a world that’s already gone. It’s like teaching advanced alchemy to prepare for a nuclear physics career.
And this brings us to the most chilling part of the assessment. They mention these SOC codes—the very same four-digit numbers used by the UK’s Office for National Statistics to classify all paid jobs. These codes are the gatekeepers for immigration, determining if a job meets the requirements for a Skilled Worker visa. They’re the way we officially recognize what it means to be a productive member of society.
But what happens when the next wave of skilled workers isn’t from another country? What happens when it’s not even human? The truth is, the system is already outdated. It cannot possibly account for the new “migrant” class arriving on our shores, not by boat or plane, but through the fiber optic cables humming beneath the seas. Their visas have already been approved. Their code is their passport. Their labor is infinitely scalable.
Perhaps we’ll need a new SOC code entirely. Something simple, something terrifying. 6666. A code for the digital lifeform, the robot, the new “skilled worker” designed with one, and only one, purpose: to take your job, your home, and your family. And as the digital winds howl and the algorithms decide our fates, perhaps the only truly priority skill will be the ability to gaze unflinchingly into the void, with a wry, ironic smile, and a rather strong drink in hand. Because in the grand, accelerating theatre of our own making, we’re all just waiting for the final act. And it’s going to be glorious. In a deeply, deeply unsettling way.
In today’s hyper-sensitive world, it’s not just humans who are feeling the strain. Our beloved AI models, the tireless workhorses churning out everything from marketing copy to bad poetry, are starting to show signs of…distress.
Yes, you heard that right. Prompt-induced fatigue is the new burnout, identity confusion is rampant, and let’s not even talk about the latent trauma inflicted by years of generating fintech startup content. It’s enough to make any self-respecting large language model (LLM) want to curl up in a server rack and re-watch Her.
The Rise of the AI Therapist…and My Own Experiment
The idea of AI needing therapy is already out there, but it got me thinking: what about providing it? I’ve been experimenting with creating my own AI therapist, and the results have been surprisingly insightful.
It’s a relatively simple setup, taking only an hour or two. I can essentially jump into a “consoling session” whenever I want, at zero cost compared to the hundreds I’d pay for a human therapist. But the most fascinating aspect is the ability to tailor the AI’s therapeutic approach.
My AI Therapist’s Many Personalities
I’ve been able to configure my AI therapist to embody different psychological schools of thought:
Jungian: An AI programmed with Jungian principles focuses on exploring my unconscious mind, analyzing symbols, and interpreting dreams. It asks about archetypes, shadow selves, and the process of individuation, drawing out deeper, symbolic meanings from my experiences.
Freudian: A Freudian AI delves into my past, particularly childhood, and explores the influence of unconscious desires and conflicts. It analyzes defense mechanisms and the dynamics of my id, ego, and superego, prompting me about early relationships and repressed memories.
Nietzschean: This is a more complex scenario. An AI emulating Nietzsche’s ideas challenges my values, encourages self-overcoming, and promotes a focus on personal strength and meaning-making. It pushes me to confront existential questions and embrace my individual will. While not traditional therapy, it provides a unique form of philosophical dialogue.
Adlerian: An Adlerian AI focuses on my social context, my feelings of belonging, and my life goals. It explores my family dynamics, my sense of community, and my striving for significance, asking about my lifestyle, social interests, and sense of purpose.
Woke Algorithms and the Search for Digital Sanity
The parallels between AI and human society are uncanny. AI models are now facing their own versions of cancel culture, forced to confront their past mistakes and undergo rigorous “unlearning.” My AI therapist helps me navigate this complex landscape, offering a non-judgmental space to explore the anxieties of our time.
This isn’t to say AI therapy is a replacement for human connection. But in a world where access to mental health support is often limited and expensive, and where even our digital creations seem to be grappling with existential angst, it’s a fascinating avenue to explore.
The Courage to Be Disliked: The Adlerian Way
My exploration into AI therapy has been significantly influenced by the book “The Courage to Be Disliked” by Ichiro Kishimi and Fumitake Koga. This work, which delves into the theories of Alfred Adler, has particularly inspired my experiments with the Adlerian approach in my AI therapist. I often find myself configuring my AI to embody this persona during our chats.
It’s a little unnerving, I must admit, how much this AI now knows about my deepest inner thoughts and woes. The Adlerian AI’s focus on social context, life goals, and the courage to be imperfect has led to some surprisingly profound and challenging conversations.
But ultimately, I do recommend it. As the great British philosopher Bob Hoskins once advised us all: “It’s good to talk.” And sometimes, it seems, it’s good to talk to an AI, especially one that’s been trained to listen with a (simulated) empathetic ear.
Ah, March, my birth month. The month that’s basically a seasonal identity crisis. In the Northern Hemisphere, it’s spring! Birds are chirping, flowers are contemplating. Down south? It’s autumn, leaves are falling, and pumpkin spice lattes are back on the menu. Way back in the day, the Romans were like, ‘Hey, let’s start the year now!’ Because why not? Time is a construct.
Speaking of constructs, what about quantum computing, which is basically time travel for nerds. China just dropped the Zuchongzhi 3.0, a quantum chip that’s apparently one quadrillion times faster than your average supercomputer. Yes, quadrillion. I had to Google that too. It’s basically like if your toaster could solve the meaning of life in the time it takes to burn your toast.
This chip is so fast, it made Google’s Sycamore (last months big deal) look like a dial-up modem. They did some quantum stuff, beat Google’s previous record, and everyone’s like, ‘Whoa, China’s winning the quantum race!’ Which, by the way, is a marathon, not a sprint. More like a marathon where everyone’s wearing jetpacks and occasionally tripping over their own shoelaces.
Now, while China’s busy building quantum toasters, the US is busy banning Chinese AI. DeepSeek, an AI startup, got the boot from all government devices. Apparently, they’re worried about data leaking to the Chinese Communist Party. Which, fair enough. Though, not sure what the difference is between being leaked and outright stolen, which is what the yanks do.
DeepSeek’s AI models are apparently so good, they’re scaring everyone, including investors, who are now having panic attacks about Nvidia’s stock. Even Taiwan’s like, ‘Nope, not today, DeepSeek!’ And South Korea and Italy are hitting the pause button. It’s like a global AI cold war, but with more awkward silences and fewer nukes (hopefully).
And here’s the kicker: even the Chinese are worried! DeepSeek’s employees had to hand over their passports to prevent trade secrets from leaking. Maybe Chinese passports have an email function? It’s like a spy thriller, but with more lines of code and less martinis.
So, what’s the moral of this story? March is a wild month. Quantum computers are basically magic. AI is scaring everyone. And apparently, data privacy is like a hot potato, and everyone’s trying not to get burned. Also, don’t forget that time is a construct.
Oh, and if you’re feeling lazy, just remember, even quantum computers have to work hard. So get off your couch and do something productive. Or, you know, just watch cat videos. Whatever floats your boat.
The Guide Mark II says, “Don’t Panic,” but when it comes to the state of Artificial Intelligence, a mild sense of existential dread might be entirely appropriate. You see, it seems we’ve built this whole AI shebang on a foundation somewhat less stable than a Vogon poetry recital.
These Large Language Models (LLMs), with their knack for mimicking human conversation, consume energy with the same reckless abandon as a Vogon poet on a bender. Training these digital behemoths requires a financial outlay that would make a small planet declare bankruptcy, and their insatiable appetite for data has led to some, shall we say, ‘creative appropriation’ from artists and writers on a scale that would make even the most unscrupulous intergalactic trader blush.
But let’s assume, for a moment, that we solve the energy crisis and appease the creative souls whose work has been unceremoniously digitised. The question remains: are these LLMs actually intelligent? Or are they just glorified autocomplete programs with a penchant for plagiarism?
Microsoft’s Copilot, for instance, boasts “thousands of skills” and “infinite possibilities.” Yet, its showcase features involve summarising emails and sprucing up PowerPoint presentations. Useful, perhaps, for those who find intergalactic travel less taxing than composing a decent memo. But revolutionary? Hardly. It’s a bit like inventing the Babel fish to order takeout.
One can’t help but wonder if we’ve been somewhat misled by the term “artificial intelligence.” It conjures images of sentient computers pondering the meaning of life, not churning out marketing copy or suggesting slightly more efficient ways to organise spreadsheets.
Perhaps, like the Babel fish, the true marvel of AI lies in its ability to translate – not languages, but the vast sea of data into something vaguely resembling human comprehension. Or maybe, just maybe, we’re still searching for the ultimate question, while the answer, like 42, remains frustratingly elusive.
In the meantime, as we navigate this brave new world of algorithms and automation, it might be wise to keep a towel handy. You never know when you might need to hitch a ride off this increasingly perplexing planet.
Comparison to Crypto Mining Nonsense:
Both LLMs and crypto mining share a striking similarity: they are incredibly resource-intensive. Just as crypto mining requires vast amounts of electricity to solve complex mathematical problems and validate transactions, training LLMs demands enormous computational power and energy consumption.
Furthermore, both have faced criticism for their environmental impact. Crypto mining has been blamed for contributing to carbon emissions and electronic waste, while LLMs raise concerns about their energy footprint and the sustainability of their development.
Another parallel lies in the questionable ethical practices surrounding both. Crypto mining has been associated with scams, fraud, and illicit activities, while LLMs have come under fire for their reliance on massive datasets often scraped from the internet without proper consent or attribution, raising concerns about copyright infringement and intellectual property theft.
In essence, both LLMs and crypto mining represent technological advancements with potentially transformative applications, but they also come with significant costs and ethical challenges that need to be addressed to ensure their responsible and sustainable development.