Available on Amazon

Available on Amazon
Writer, Scribbler and Prompt Alchemist
We’ve identified the enemy. It is the Activity Demon, the creature that feeds on the performance of work and starves the business of results. We know its weakness: the cold, hard language of the balance sheet.
Now, we move from defence to offence.

A resistance cannot win by writing a better play; it must sabotage the production itself. For each of the five acts in the SHAPE framework, there is a counter-measure—a piece of tactical sabotage designed to disrupt the performance and force reality onto the stage. This is the saboteur’s handbook.
Sabotage Tactic #1: To Counterfeit Strategic Agility… Build the Project Guillotine. The performance of agility is a carefully choreographed dance of rearranging timelines. The sabotage is to build a real consequence engine. Every project begins with a public, metric-driven “kill switch.” If user adoption doesn’t hit 10% in 45 days, the project is terminated. If it doesn’t reduce server costs by X amount in 90 days, it’s terminated. The guillotine is automated. It requires no committee, no appeal. It makes pivoting real because the alternative is death, not just a rewrite.
Sabotage Tactic #2: To Counterfeit Human Centricity… Give the Audience a Veto. The performance of empathy is the scripted Q&A where softballs are thrown and no one is truly heard. The sabotage is to form a “User Shadow Council”—a rotating group of the actual end-users who will be most affected. They are given genuine power: a non-negotiable veto at two separate stages of development. It’s no longer a performance of listening; it’s a hostage negotiation with the people you claim to be helping.
Sabotage Tactic #3: To Counterfeit Applied Curiosity… Make the Leaders Bleed. The performance of curiosity is delegating “exploration” to a junior team. The sabotage is the “Blood in the Game” rule. Once a quarter, every leader on the executive team must personally run a small, cheap, fast experiment and present their raw, unfiltered findings. No proxies. No polished decks. They must get their own hands dirty to show that curiosity is a messy, risky practice, not a clean performance watched from a safe distance.
Sabotage Tactic #4: To Counterfeit Performance Drive… Chain the Pilot to its Scaled Twin. The performance of drive is the standing ovation for the pilot, with no second act. The sabotage is the “Scaled Twin Mandate.” No pilot program can receive funding without an accompanying, pre-approved, fully-funded scaling plan. The moment the pilot meets its success criteria, that scaling plan is automatically triggered. The pilot is no longer the show; it’s just the fuse on the rocket.
Sabotage Tactic #5: To Counterfeit Ethical Stewardship… Unleash the Red Team. The performance of ethics is a PR clean-up operation. The sabotage is to fund an independent, internal “Red Team” from day one. Their sole purpose is to be a hostile attacker. Their job is to find and publicly expose the project’s ethical flaws and biases. Their success is measured by how much damage they can do to the project before it ever sees the light of day. This makes ethics a core part of the design, not the apology tour.

These tactics are dangerous. They will be met with resistance from those who are comfortable in the theater. But the real horror isn’t failing. The real horror is succeeding at a performance that never mattered, while the world outside the theatre walls moved on without you. The set is just wood and canvas. It’s time to start tearing it down.
The lights are dim. In the sterile conference room, under the low hum of the servers, the show is about to begin. This isn’t Broadway. This is the “pilot theater,” the grand stage where innovation is performed, not delivered. We see the impressive demos, the slick dashboards, the confident talk of transformation. It’s a magnificent production. But pull back the curtain, and you’ll find him: a nervous man, bathed in the glow of a monitor, frantically pulling levers. He’s following a script, a framework, a process so perfectly executed that everyone has forgotten to ask if the city of Oz he’s projecting is even real.

The data, when you can find it in the dark, is grim. A staggering 95% of generative AI programs fail to deliver any real value. The stage is littered with the ghosts of failed pilots. We’ve become so obsessed with the performance of progress that we’ve forgotten the point of it. The man behind the curtain is a master of Agile ceremonies, his stand-ups are flawless, his retrospectives insightful. He can tell you, with perfect clarity, that the team followed the process beautifully. But when you ask him what they were supposed to be delivering, his eyes go blank. The script didn’t mention that part.
And now, a new script has arrived. It has a name, of course. They always do. This one is called SHAPE.
The SHAPE index was born from the wreckage of that 95%. It’s a framework meant to identify the five key behaviors of leaders who can actually escape the theater and build something real. It’s supposed to be our map out of Oz. But in a world that worships the map over the destination, we must ask: Is this a tool for the leader, or is the leader just becoming a better-trained tool for the framework? Is this a way out, or just a more elaborate set of levers to pull?
Let’s look at the five acts of this new play.
The script says a leader must plan for the long term while pivoting in the short term. In the theater, this is a beautiful piece of choreography. The leader stands at the whiteboard, decisively moving charts around, declaring a “pivot.” It looks like genius. It feels like action. But too often, it’s just rearranging the props on stage. The underlying set—the core business problem—remains unchanged. The applause is for the performance of agility, not the achievement of a better position.
Here, the actor-leader must perform empathy. They must quell the rising anxiety of the workforce. The mantra, repeated with a fixed smile, is: “AI will make humans better.” It sounds reassuring, but the chill remains. The change is designed in closed rooms and rolled out from the top down. Psychological safety isn’t a culture; it’s a talking point in a town hall. The goal isn’t to build trust, but to manage dissent just enough to keep the show from being cancelled.
This act requires the leader to separate signal from the deafening hype. So, the theater puts on a dazzling display of “disciplined experimentation.” New, shiny AI toys are paraded across the stage. Each pilot has a clear learning objective, a report is dutifully filed, and then… nothing. The learning isn’t applied; it’s archived. The point was never to learn; it was to be seen learning. The experiments are just another scene, designed to convince the audience that something, anything, is happening.

This is where the term “pilot theater” comes directly from the script. The curtain falls on the pilot, and the applause is thunderous. Success is declared. But when you ask what happens next, how it scales, how it delivers that fabled ROI, you’re met with silence. The cast is already rehearsing for the next pilot, the next opening night. Success is measured in the activity of the performance, not the revenue at the box office. The show is celebrated, but the business quietly bleeds.
The final, haunting act. This part of the script is often left on the floor, only picked up when a crisis erupts. A reporter calls. A dataset is found to be biased. Suddenly, the theater puts on a frantic, ad-libbed performance of responsibility. Governance is bolted on like a cheap prop. It’s an afterthought, a desperate attempt to manage the fallout after the curtain has been torn down and the audience sees the wizard for what he is: just a man, following a script that was fundamentally flawed from the start.
The good news, the researchers tell us, is that these five SHAPE capabilities can be taught. It’s a comforting thought. But in the eerie glow of the pilot theater, a darker question emerges: Are we teaching leaders to be effective, or are we just teaching them to be better actors?
We’ve been here before with Agile, with Six Sigma, with every framework that promised a revolution and instead delivered a new form of ritual. We perfect the process and forget the purpose. We fall in love with the intricate levers and the booming voice they produce, and we never step out from behind the curtain to see if anyone is even listening anymore.
The SHAPE index gives us a language to describe the leaders we need. But it also gives us a new, more sophisticated script to hide behind. And as we stand here, in the perpetual twilight of the pilot theater, the most important question isn’t whether our leaders have SHAPE. It’s whether we are the shapers, or if we are merely, and quietly, being shaped.

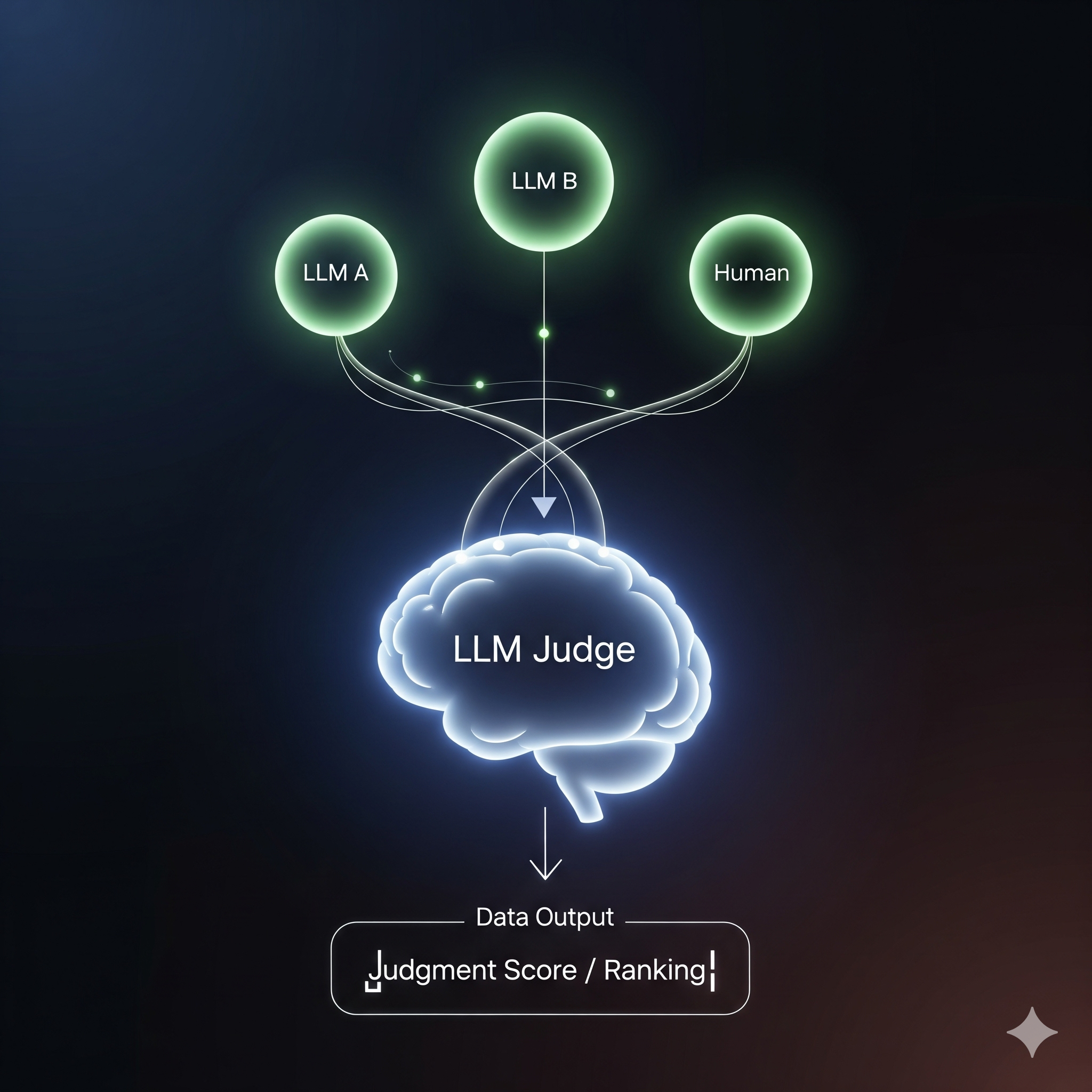
As the complexity and ubiquity of artificial intelligence models, particularly Large Language Models (LLMs), continue to grow, the need for robust, scalable, and nuanced evaluation frameworks has become paramount. Traditional evaluation methods, often relying on statistical metrics or limited human review, are increasingly insufficient for assessing the qualitative aspects of modern AI outputs—such as helpfulness, empathy, cultural appropriateness, and creative coherence. This challenge has given rise to an innovative paradigm: using LLMs themselves as “judges” to evaluate the outputs of other models. This approach, often referred to as LLM-as-a-Judge, represents a significant leap forward, offering a scalable and sophisticated alternative to conventional methods.
Traditional evaluation is fraught with limitations. Manual human assessment, while providing invaluable insight, is notoriously slow and expensive. It is susceptible to confounding factors, inherent biases, and can only ever cover a fraction of the vast output space, missing a significant number of factual errors. These shortcomings can lead to harmful feedback loops that impede model improvement. In contrast, the LLM-as-a-Judge approach provides a suite of compelling advantages:
There are several scoring approaches to consider when implementing an LLM-as-a-Judge system. Single output scoring assesses one response in isolation, either with or without a reference answer. The most powerful method, however, is pairwise comparison, which presents two outputs side-by-side and asks the judge to determine which is superior. This method, which most closely mirrors the process of a human reviewer, has proven to be particularly effective in minimizing bias and producing highly reliable results.
When is it appropriate to use LLM-as-a-Judge? This approach is best suited for tasks requiring a high degree of qualitative assessment, such as summarization, creative writing, or conversational AI. It is an indispensable tool for a comprehensive evaluation framework, complementing rather than replacing traditional metrics.
While immensely powerful, the LLM-as-a-Judge paradigm is not without its own set of challenges, most notably the introduction of subtle, yet impactful, evaluation biases. A clear understanding and mitigation of these biases is critical for ensuring the integrity of the assessment process.
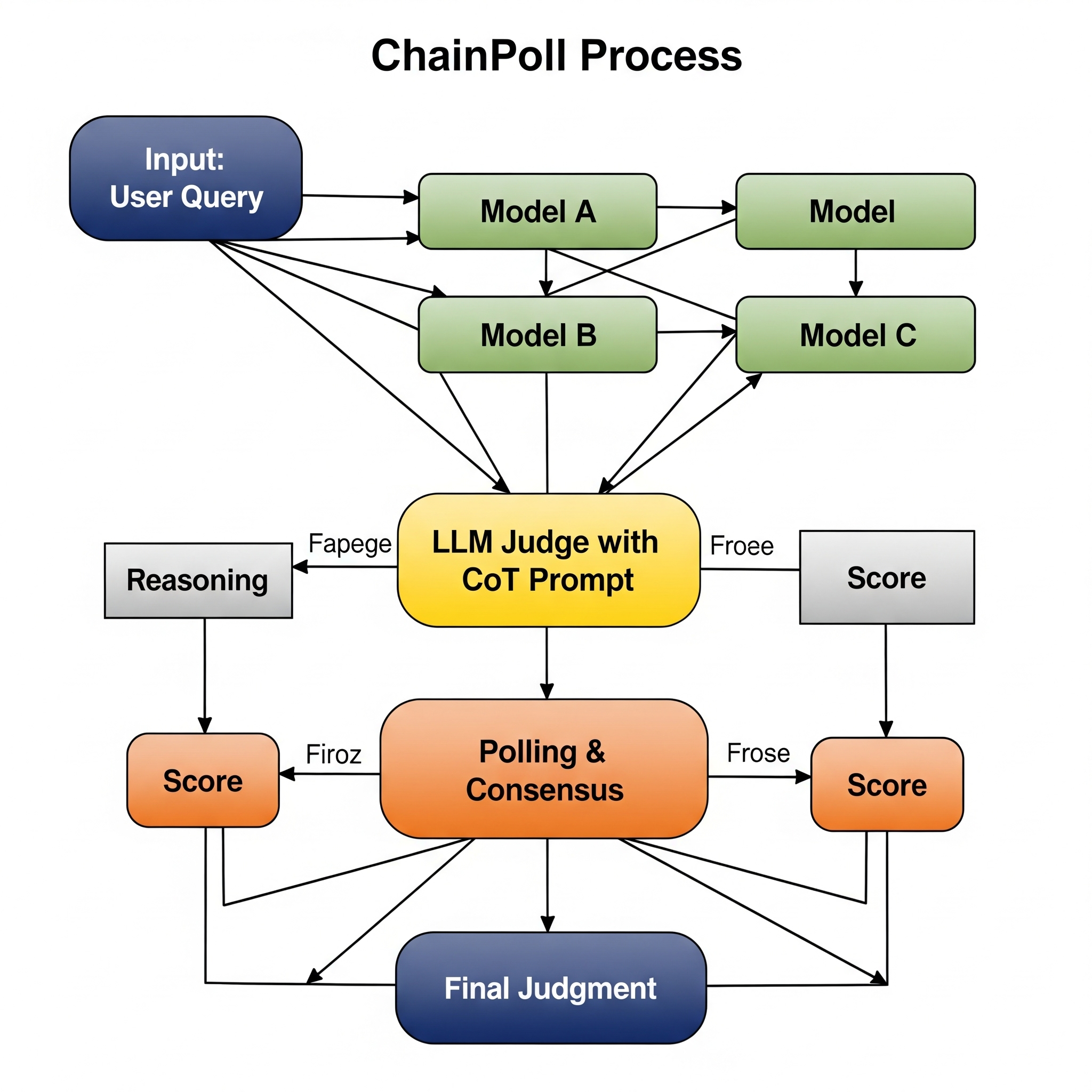
To combat these pitfalls, researchers at Galileo have developed the “ChainPoll” approach. This method marries the power of Chain-of-Thought (CoT) prompting—where the judge is instructed to reason through its decision-making process—with a polling mechanism that presents the same query to multiple LLMs. By combining reasoning with a consensus mechanism, ChainPoll provides a more robust and nuanced assessment, ensuring a judgment is not based on a single, potentially biased, point of view.
A real-world case study at LinkedIn demonstrated the effectiveness of this approach. By using an LLM-as-a-Judge system with ChainPoll, they were able to automate a significant portion of their content quality evaluations, achieving over 90% agreement with human raters at a fraction of the time and cost.
While larger models like Google’s Gemini 2.5 are the gold standard for complex, nuanced evaluations, the role of specialised Small Language Models (SLMs) is rapidly gaining traction. SLMs are smaller, more focused models that are fine-tuned for a specific evaluation task, offering several key advantages over their larger counterparts.
Galileo’s latest offering, Luna 2, exemplifies this trend. Luna 2 is a new generation of SLM specifically designed to provide low-latency, low-cost metric evaluations. Its architecture is optimized for speed and accuracy, making it an ideal candidate for tasks such as sentiment analysis, toxicity detection, and basic factual verification where a large, expensive LLM may be overkill.
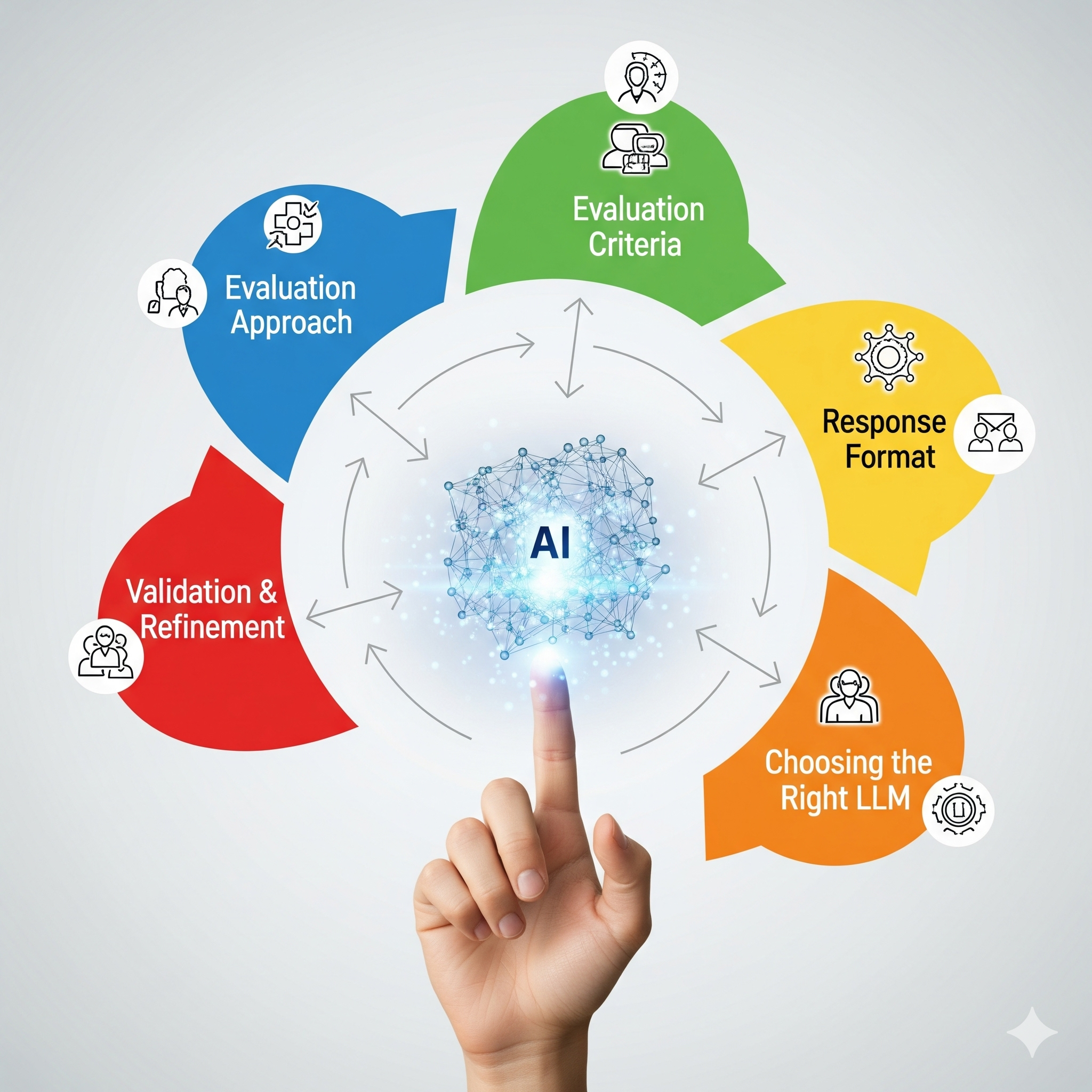
Building a reliable LLM judge is an art and a science. It requires a thoughtful approach to five key components.
The following is a simplified, conceptual example of how a core LLM judge function might be configured:
def create_llm_judge_prompt(evaluation_criteria, user_query, candidate_responses):
"""
Constructs a detailed prompt for an LLM judge.
"""
prompt = f"""
You are an expert evaluator of AI responses. Your task is to judge and rank the following responses
to a user query based on the following criteria:
Criteria:
{evaluation_criteria}
User Query:
"{user_query}"
Candidate Responses:
Response A: "{candidate_responses['A']}"
Response B: "{candidate_responses['B']}"
Instructions:
1. Think step-by-step and write your reasoning.
2. Based on your reasoning, provide a final ranking of the responses.
3. Your final output must be in JSON format: {{"reasoning": "...", "ranking": {{"A": "...", "B": "..."}}}}
"""
return prompt
def validate_llm_judge(judge_function, test_data, metrics):
"""
Validates the performance of the LLM judge against a human-labeled dataset.
"""
judgements = []
for test_case in test_data:
prompt = create_llm_judge_prompt(test_case['criteria'], test_case['query'], test_case['responses'])
llm_output = judge_function(prompt) # This would be your API call to Gemini 2.5
judgements.append({
'llm_ranking': llm_output['ranking'],
'human_ranking': test_case['human_ranking']
})
# Calculate metrics like precision, recall, and Cohen's Kappa
# based on the judgements list.
return calculate_metrics(judgements, metrics)
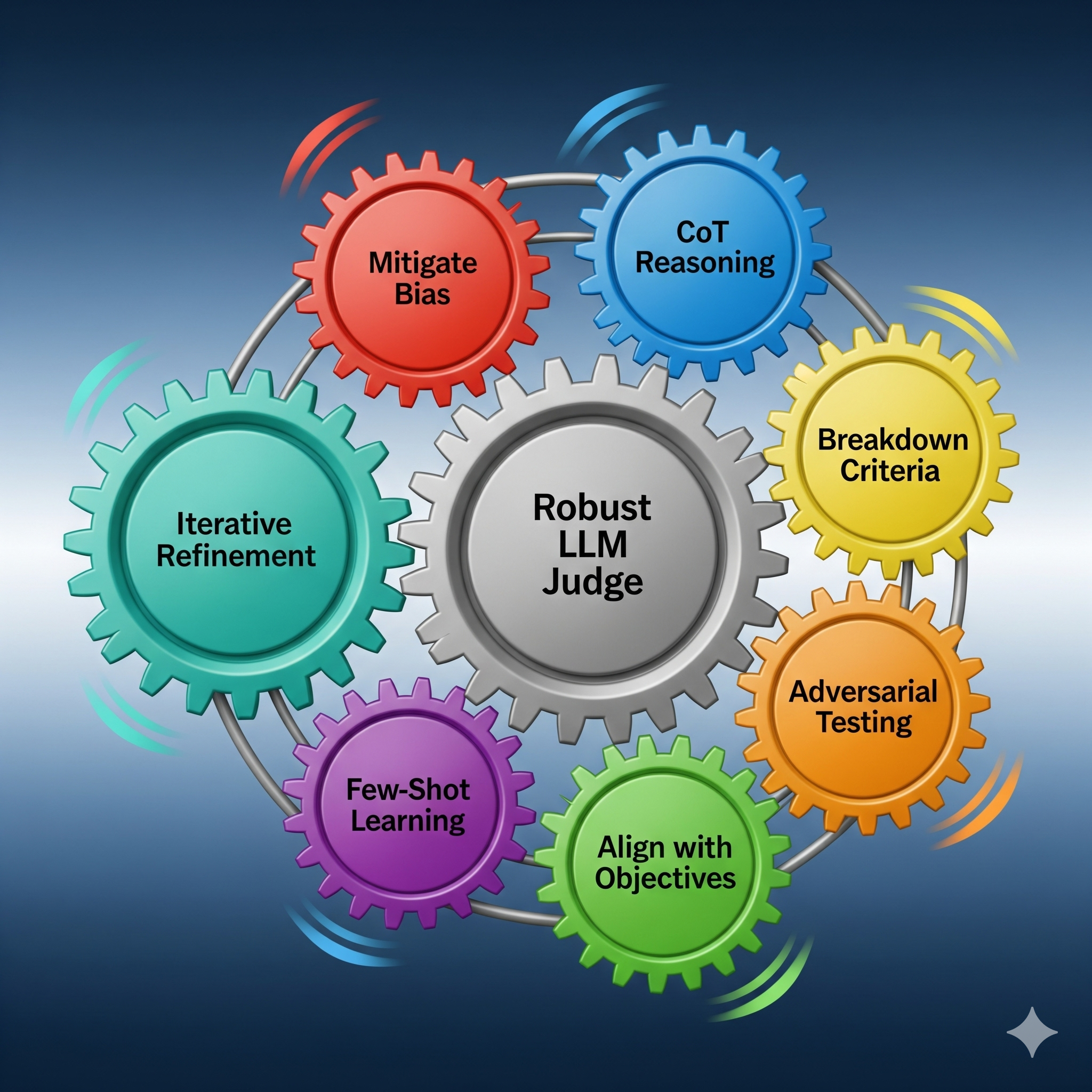
Building upon the foundational best practices, there are seven practical enhancements that can dramatically improve the reliability and consistency of your LLM judge.
By synthesizing these strategies into a comprehensive toolbox, we can build a highly robust and reliable LLM judge. Ultimately, the effectiveness of any LLM-as-a-Judge system is contingent on the underlying model’s reasoning capabilities and its ability to handle complex, open-ended tasks. While many models can perform this function, our extensive research and testing have consistently shown that Google’s Gemini 2.5 outperforms its peers in the majority of evaluation scenarios. Its advanced reasoning and nuanced understanding of context make it the definitive choice for building an accurate, scalable, and sophisticated evaluation framework.

There is a theory which states that if ever anyone discovers exactly what the business world is for, it will instantly disappear and be replaced by something even more bizarre and inexplicable. There is another theory which states that this has already happened. This certainly goes a long way to explaining the current corporate strategy for dealing with Artificial Intelligence, which is to largely ignore it, in the same way that a startled periwinkle might ignore an oncoming bulldozer, hoping that if it doesn’t make any sudden moves the whole “unsettling” situation will simply settle down.
This is, of course, a terrible strategy, because while everyone is busy not looking, the bulldozer is not only getting closer, it’s also learning to draw a surprisingly good, yet legally dubious, cartoon mouse.
We live in an age of what is fashionably called “Agile,” a term which here seems to mean “The Art of Controlled Panic.” It’s a frantic, permanent state of trying to build the aeroplane while it’s already taxiing down the runway, fueled by lukewarm coffee and a deep-seated fear of the next quarterly review. For years, the panic-release valve was off-shoring. When a project was on fire, you could simply bundle up your barely coherent requirements and fling them over the digital fence to a team in another time zone, hoping they’d throw back a working solution before morning.
Now, we have perfected this model. AI is the new, ultimate off-shoring. The team is infinitely scalable, works for pennies, and is located somewhere so remote it isn’t even on a map. It’s in “The Cloud,” a place that is reassuringly vague and requires no knowledge of geography whatsoever.

The problem is, this new team is a bit weird. You still need that one, increasingly stressed-out human—let’s call them the Prompt Whisperer—to translate the frantic, contradictory demands of the business into a language the machine will understand. They are the new middle manager, bridging the vast, terrifying gap between human chaos and silicon logic. But there’s a new, far more alarming, item in their job description.
You see, the reason this new offshore team is so knowledgeable is because it has been trained by binge-watching the entire internet. Every film, every book, every brand logo, every cat picture, and every episode of every cartoon ever made. And as the ongoing legal spat between the Disney/Universal behemoth and the AI art platform Midjourney demonstrates, the hangover from this creative binge is about to kick in with the force of a Pan Galactic Gargle Blaster.
The issue, for any small business cheerfully using an AI to design their new logo, is one of copyright. In the US, they have a principle called “fair use,” which is a wonderfully flexible and often confusing set of rules. In the UK, we have “fair dealing,” which is a narrower, more limited set of rules that is, in its own way, just as confusing. If the difference between the two seems unclear, then congratulations, you have understood the central point perfectly: you are almost certainly in trouble.
The AI, you see, doesn’t create. It remixes. And it has no concept of ownership. Ask it to design a logo for your artisanal doughnut shop, and it might cheerfully serve up something that looks uncannily like the beloved mascot of a multi-billion-dollar entertainment conglomerate. The AI isn’t your co-conspirator; it’s the unthinking photocopier, and you’re the one left holding the legally radioactive copy. Your brilliant, cost-effective branding exercise has just become a business-ending legal event.
So, here we are, practicing the art of controlled panic on a legal minefield. The new off-shored intelligence is a powerful, dangerous, and creatively promiscuous force. That poor Prompt Whisperer isn’t just briefing the machine anymore; they are its parole officer, desperately trying to stop it from cheerfully plagiarizing its way into oblivion. The only thing that hasn’t “settled down” is the dust from the first wave of cease-and-desist letters. And they are, I assure you, on their way.


Today is August 15th, and while India celebrates its Independence Day with vibrant parades and patriotic fervour, the world stands on a precipice. The storm clouds of conflict gathering over the Persian Gulf are not just another geopolitical squall; they are the harbingers of a global reset. The bitter, resentful revenge of a cornered nation is about to create the power vacuum that a patient, rising superpower has been quietly preparing to fill. This is a tale of two futures: one of a spectacular, self-inflicted collapse, and the other of a quiet, inexorable ascent.
Warren Buffett famously called derivatives “financial weapons of mass destruction.” He wasn’t being metaphorical. He was describing a doomsday device embedded in the heart of our global financial system, waiting for a trigger. That trigger is now being pulled in the escalating conflict between the US, Israel, and Iran.
Iran’s revenge will not be a conventional war it cannot win. Its true trump card is a geopolitical choke point: the Strait of Hormuz. By shutting down this narrow waterway, Iran can instantly remove 20% of the world’s daily oil supply from the market. To put that in perspective, the 1973 oil crisis that quadrupled prices was caused by a mere 9% supply shock. A 20% shock is an extinction-level event for the global economy as we know it.
This isn’t a problem central banks can solve by printing money; they cannot print oil. The immediate price surge to well over $275 a barrel would act as the detonator for Buffett’s financial WMDs. The derivatives market, built on a tangled web of bets on oil prices, would implode. We would see a cascade of margin calls, defaults, and liquidity crises that would make 2008 look like a minor tremor. This is Iran’s asymmetric revenge: a single move that cripples its adversary by turning the West’s complex financial system against itself. The era of the US policing the world would end overnight, not with a bang, but with the silent, terrifying seizure of the global economic heart.
And as the old order chokes on its own hubris, a new one rises. Today, on its Independence Day, India isn’t just celebrating its past; it’s stepping into its future. While the West has been consumed with military dominance and policing the globe, India has been playing a different, longer game. Its strategy is not one of confrontation, but of strategic patience and relentless economic acquisition.
As the US fractures under the weight of economic collapse and internal strife, India will not send armies; it will send dealmakers. For years, it has been quietly and methodically getting on with the real business of building an empire:
This is not the loud, coercive power of the 20th century. It is a quiet, intelligent expansion built on economic partnership and a philosophy of multi-alignment. While America was spending trillions on wars, India has been investing its capital to build the foundations of the 21st-century’s dominant power.
The chaos born from the Scorpion’s sting provides the perfect cover for the Phoenix’s rise. As the West reels from an economic crisis it cannot solve, India, having maintained its neutrality, will step into the void. It will be the lender, the buyer, the partner of last resort. Today’s Independence Day marks the turning point. The world’s attention is on the explosion in the Gulf, but the real story is the quiet construction of a new world order, architected in New Delhi.
Down in the doom-scroll trenches, the memes about the Strait of Hormuz are getting spicier. Someone’s even set up a 24/7 livestream of the tanker routes with a synthwave soundtrack, already sponsored by a VPN. We’re all watching the end of the world like it’s a product launch, waiting to see if it drops on time and if we get the pre-order bonus. The collapse of empire, it turns out, is not a bug; it’s a feature.
The suits in DC and Tel Aviv finally swiped right on a war with Iran, and now the payback is coming. Not as a missile, but as a glitch in the matrix of global commerce. Iran’s revenge is to press CTRL+ALT+DEL on the Strait of Hormuz, that tiny pixel of water through which 20% of the world’s liquid motivation flows. Warren Buffett, bless his folksy, analogue heart, called derivatives “financial weapons of mass destruction.” He was thinking of numbers on a screen. He wasn’t thinking of the vurt-feathers and data-ghosts that truly haunt the system—toxic financial spells cooked up by algorithmic daemons in sub-zero server farms. The 20% oil shock isn’t a market correction; it’s a scream in the machine, a fever that boils those probability-specters into a vengeful, system-crashing poltergeist. Central banks can’t exorcise this demon with printed money. You can’t fight a ghost with paper.
And so the Great Unsubscribe begins. One morning you’ll wake up and your smart-fridge will have cancelled your avocado subscription, citing “unforeseen geopolitical realignments.” The ATMs won’t just be out of cash; they’ll dispense receipts with cryptic, vaguely philosophical error messages that will become a new form of street art. The American Civil War everyone LARP’d about online won’t be fought with guns; it’ll be fought between algorithm-fueled flash-mobs in states that are now just corporate fiefdoms—the Amazon Protectorate of Cascadia versus the United Disney Emirates of Florida. Your gig-economy rating will plummet because you were too busy bartering protein paste for Wi-Fi to deliver a retro-ironic vinyl record on time. The empire doesn’t end with a bang; it ends with a cascade of notifications telling you your lifestyle has been deprecated.
Meanwhile, the real story is happening elsewhere, humming quietly beneath the noise of the Western world’s noisy, spectacular nervous breakdown. India, the patient subcontinent, is not launching an invasion; it’s executing a hostile takeover disguised as a wellness retreat. As America’s brand identity fractures, India’s dealmakers move like pollen-priests on the wind, not buying companies so much as metabolizing them. Their power isn’t in aircraft carriers; it’s in the elegant, undeniable logic of the code being written in Bangalore that now runs the logistics for a port in Africa that used to have a US flag flying over it. It’s a reverse-colonization happening at the speed of light, a bloodless coup fought on spreadsheets and in server racks, utterly unnoticed by a populace busy arguing over the last can of artisanal kombucha.
The future has already happened; we’re just waiting for the update to finish installing. On a rooftop in Mumbai, a kid is beta-testing a neural interface powered by a chip designed in what used to be called Silicon Valley. On a cracked pavement in what used to be California, another kid is trying to trade a vintage, non-functional iPhone for a bottle of clean water. The global operating system has been rebooted. Today isn’t just India’s Independence Day. It’s the day the rest of the world realized their free trial had expired.
Happy Independence Day to all my Indian friends – may the next century be peacefully yours.
Prem (प्रेम) Shanti (शान्ति) Safalta (सफलता) Khushi (ख़ुशी)
So, LinkedIn, in its infinite, algorithmically-optimised wisdom, sent me an email and posed a question: Has generative AI transformed how you hire?

Oh, you sweet, innocent, content-moderated darlings. Has the introduction of the self-service checkout had any minor, barely noticeable effect on the traditional art of conversing with a cashier? Has the relentless efficiency of Amazon Prime in any way altered our nostalgic attachment to a Saturday afternoon browse down the local high street? Has the invention of streaming services had any small impact on the business model of your local Blockbuster video?
Yes. Duh.
You see, the modern hiring process is no longer about finding a person for a role. It is a wonderfully ironic Turing Test in reverse. The candidate, a squishy carbon-based lifeform full of anxieties and a worrying coffee dependency, uses a vast, non-sentient silicon brain to convince you they are worthy. You, another squishy carbon-based lifeform, must then use your own flawed, meat-based intuition to decide if the ghost in their machine is a good fit for the ghost in your machine.
The CV is dead. It is a relic, a beautifully formatted PDF of lies composed by a language model that has read every CV ever written and concluded that the ideal candidate is a rock-climbing, volunteer-firefighting, Python-coding polymath who is “passionate about synergy.” The cover letter? It’s a work of algorithmically generated fiction, a poignant, computer-dreamed ode to a job it doesn’t understand for a company it has never heard of.
So, are you hiring a person, or the AI-powered spectre of that person? A LinkedIn profile is no longer a testament to a career; it’s a monument to successful prompt engineering.
To truly prove consciousness in 2025, a candidate needs a blog. A podcast. A YouTube channel where they film themselves, unshaven and twitching, wrestling with a piece of code while muttering about the futility of existence. We require a verifiable, time-stamped proof of life to show they haven’t simply outsourced their entire professional identity to a subscription service.
Meanwhile, the Great Career Shuffle accelerates. An entire car-crash multitude of ex-banking staff, their faces etched with the horror of irrelevance, are now desperately rebranding as “AI strategists.” The banks themselves are becoming quaint, like steam museums, while the real action—the glorious, three-month contracts of frantic, venture-capital-fueled chaos—is in the AI startups.
It all feels so familiar. It’s that old freelance feeling, where your CV wasn’t a document but a long list of weapons in your arsenal. You needed a bow with a string for every conceivable software battle. One week it was pure HTML+CSS. The next, you were a warrior in the trenches of the Great Plugin Wars, wrestling the bloated, beautiful behemoth of Flash until, almost overnight, it was rendered obsolete by the sleek, sanctimonious assassin that was HTML5.
The backend was a wilder frontier. A company demanded you wrestle with the hydra of PHP, be it WordPress, Drupal, or the dark arts of Magento if a checkout was involved. For a brief, shining moment, everything was meant to be built on the elegant railway tracks of Ruby. Then came the Javascript Tsunami, a wave so vast it swept over both the front and back ends, leaving a tangled mess that developers are still trying to untangle to this day.
And the enterprise world? A mandatory pilgrimage to the great, unkillable temple of Java. The backend architecture evolved from the stuffy, formal rituals of SOAP APIs to the breezy, freewheeling informality of REST. Then came the Great Atomisation, an obsession with breaking monoliths into a thousand tiny microservices, putting each one in a little digital box with Docker, and then hiring an entirely new army of engineers just to plumb all the boxes back together again. If you had a bit of COBOL, the banks would pay you a king’s ransom to poke their digital dinosaurs. A splash of SQL always won the day.
On top of all this, the Agile evangelists descended, an army of Scrum Masters who achieved sentience overnight and promptly promoted themselves to “Agile Coaches,” selling certifications and a brand of corporate mindfulness that fixed precisely nothing. All of it, every last trend, every rise and fall and rise again of Java, was just a slow, inexorable death march towards the beige, soul-crushing mediocracy of the Microsoft stack—a sprawling empire of .NET and Azure so bland and full of holes that every junior hacker treats it as a welcome mat.
AI is just the latest, shiniest weapon to add to the rack.
So, in the spirit of this challenge, here are my Top Tips for Candidates Navigating This New World:
The whole thing is, of course, gloriously absurd. We are using counterfeit intelligence to apply for counterfeit jobs in a counterfeit economy. And we have the audacity to call it progress.
#LinkedInNewsEurope

In a world increasingly powered by AI, geopolitical tension, and the lingering mystery of where your socks actually go, the sheer, unadulterated nonsense of it all has finally caught up. It’s gotten so wonderfully, ridiculously absurd that plain old prose just won’t cut it anymore. So, for the next few days, I’m ditching logic, embracing the lyrical, and discussing the modern world—including the baffling beauty of Agile methodologies—one witty limerick at a time. Prepare for rhyme, rhythm, and possibly a sudden urge to tap your foot.
A keen Agile team, quite precise,
Gave old Waterfall sound advice.
"For sprints short and bright,
We code through the night,
Fuelled by coffee, at any old price!"

In a world increasingly powered by AI, geopolitical tension, and the lingering mystery of where your socks actually go, the sheer, unadulterated nonsense of it all has finally caught up. It’s gotten so wonderfully, ridiculously absurd that plain old prose just won’t cut it anymore. So, for the next few days, I’m ditching logic, embracing the lyrical, and discussing the modern world—including the baffling beauty of Agile methodologies—one witty limerick at a time. Prepare for rhyme, rhythm, and possibly a sudden urge to tap your foot.
A keen Agile team, quite precise,
Gave old Waterfall sound advice.
"For sprints short and bright,
We code through the night,
Fuelled by coffee, at any old price!"