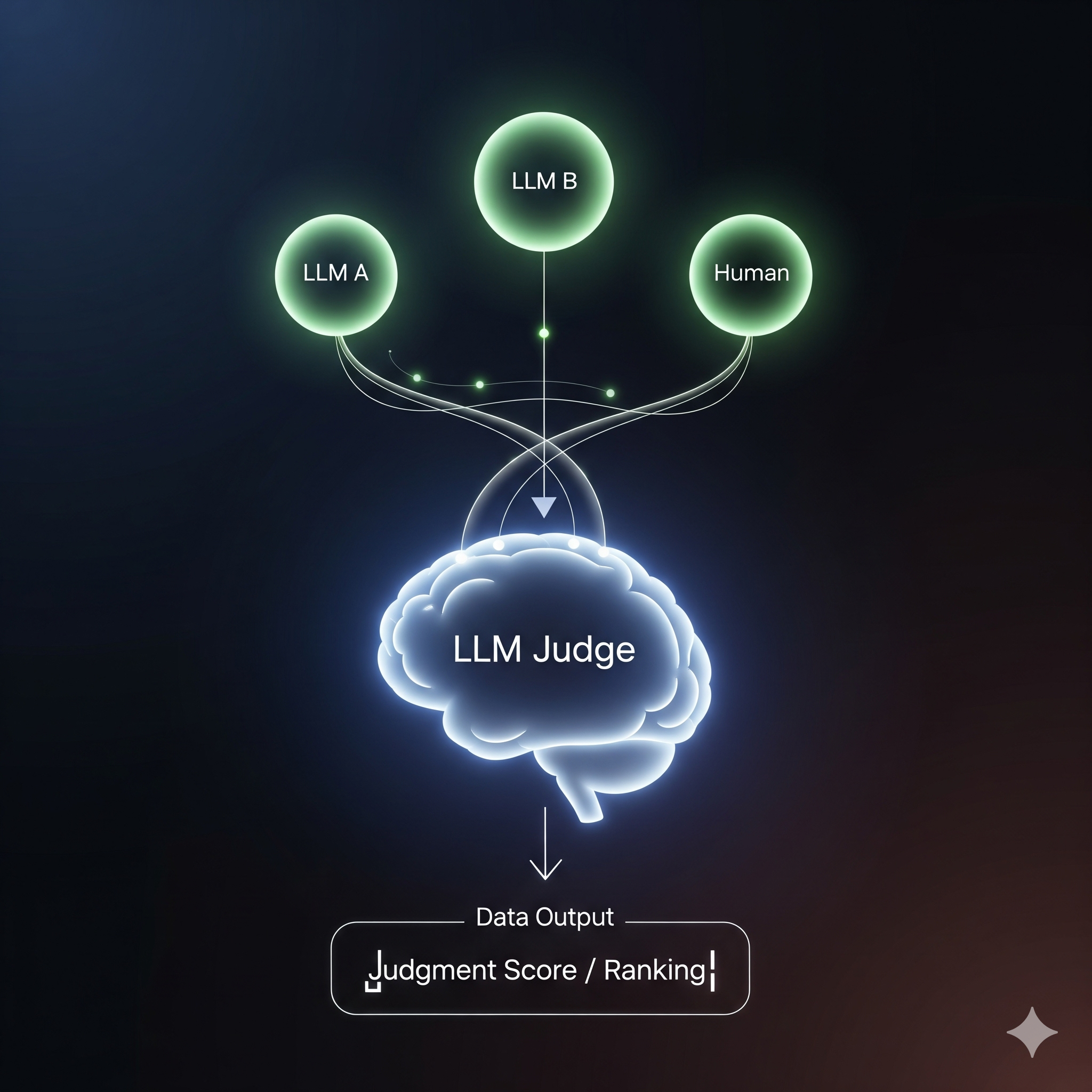
An Introduction to a New Paradigm in AI Assessment
As the complexity and ubiquity of artificial intelligence models, particularly Large Language Models (LLMs), continue to grow, the need for robust, scalable, and nuanced evaluation frameworks has become paramount. Traditional evaluation methods, often relying on statistical metrics or limited human review, are increasingly insufficient for assessing the qualitative aspects of modern AI outputs—such as helpfulness, empathy, cultural appropriateness, and creative coherence. This challenge has given rise to an innovative paradigm: using LLMs themselves as “judges” to evaluate the outputs of other models. This approach, often referred to as LLM-as-a-Judge, represents a significant leap forward, offering a scalable and sophisticated alternative to conventional methods.
Traditional evaluation is fraught with limitations. Manual human assessment, while providing invaluable insight, is notoriously slow and expensive. It is susceptible to confounding factors, inherent biases, and can only ever cover a fraction of the vast output space, missing a significant number of factual errors. These shortcomings can lead to harmful feedback loops that impede model improvement. In contrast, the LLM-as-a-Judge approach provides a suite of compelling advantages:
- Scalability: An LLM judge can evaluate millions of outputs with a speed and consistency that no human team could ever match.
- Complex Understanding: LLMs possess a deep semantic and contextual understanding, allowing them to assess nuances that are beyond the scope of simple statistical metrics.
- Cost-Effectiveness: Once a judging model is selected and configured, the cost per evaluation is a tiny fraction of a human’s time.
- Flexibility: The evaluation criteria can be adjusted on the fly with a simple change in the prompt, allowing for rapid iteration and adaptation to new tasks.
There are several scoring approaches to consider when implementing an LLM-as-a-Judge system. Single output scoring assesses one response in isolation, either with or without a reference answer. The most powerful method, however, is pairwise comparison, which presents two outputs side-by-side and asks the judge to determine which is superior. This method, which most closely mirrors the process of a human reviewer, has proven to be particularly effective in minimizing bias and producing highly reliable results.
When is it appropriate to use LLM-as-a-Judge? This approach is best suited for tasks requiring a high degree of qualitative assessment, such as summarization, creative writing, or conversational AI. It is an indispensable tool for a comprehensive evaluation framework, complementing rather than replacing traditional metrics.
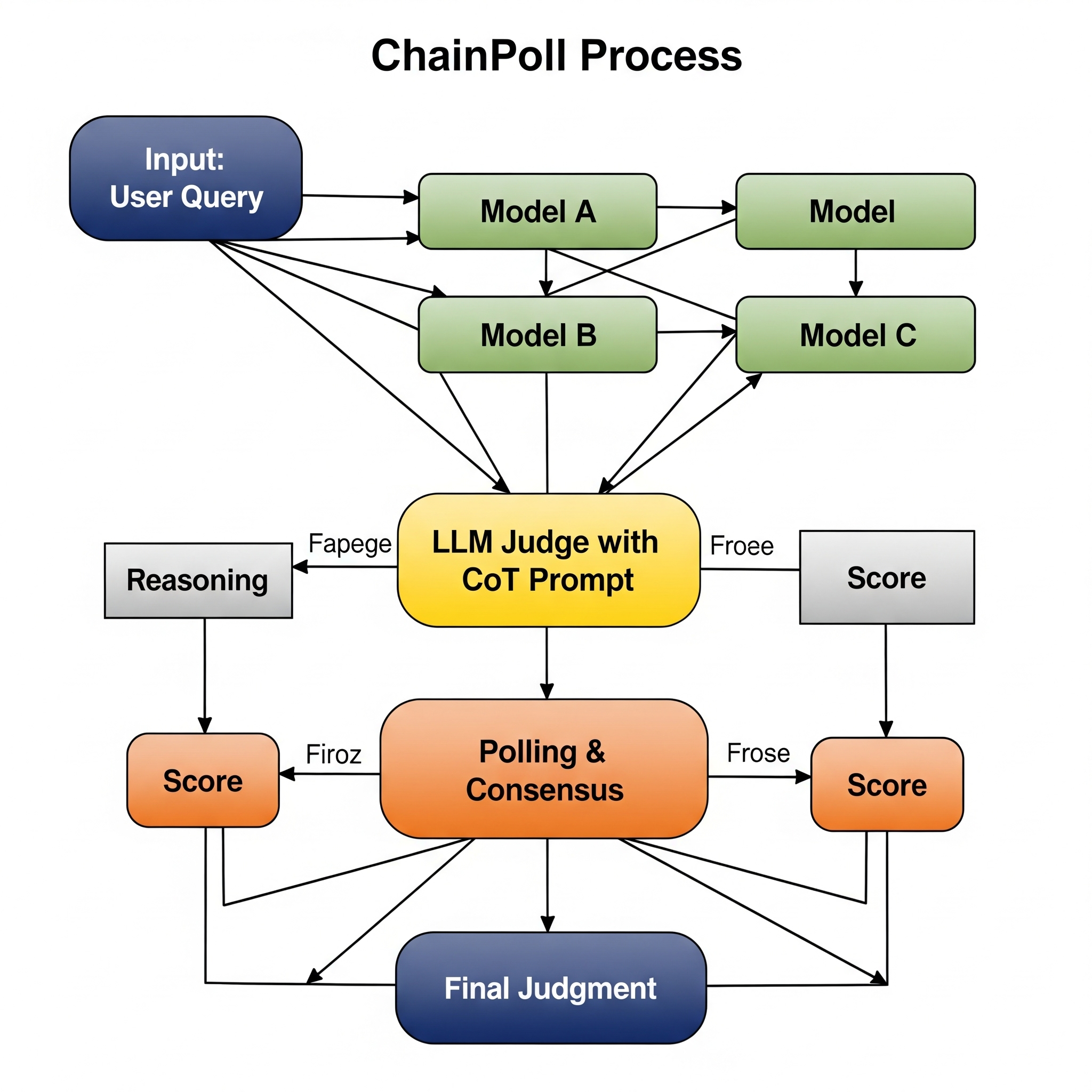
Challenges With LLM Evaluation Techniques
While immensely powerful, the LLM-as-a-Judge paradigm is not without its own set of challenges, most notably the introduction of subtle, yet impactful, evaluation biases. A clear understanding and mitigation of these biases is critical for ensuring the integrity of the assessment process.
- Nepotism Bias: The tendency of an LLM judge to favor content generated by a model from the same family or architecture.
- Verbosity Bias: The mistaken assumption that a longer, more verbose answer is inherently better or more comprehensive.
- Authority Bias: Granting undue credibility to an answer that cites a seemingly authoritative but unverified source.
- Positional Bias: A common bias in pairwise comparison where the judge consistently favors the first or last response in the sequence.
- Beauty Bias: Prioritizing outputs that are well-formatted, aesthetically pleasing, or contain engaging prose over those that are factually accurate but presented plainly.
- Attention Bias: A judge’s focus on the beginning and end of a lengthy response, leading it to miss critical information or errors in the middle.
To combat these pitfalls, researchers at Galileo have developed the “ChainPoll” approach. This method marries the power of Chain-of-Thought (CoT) prompting—where the judge is instructed to reason through its decision-making process—with a polling mechanism that presents the same query to multiple LLMs. By combining reasoning with a consensus mechanism, ChainPoll provides a more robust and nuanced assessment, ensuring a judgment is not based on a single, potentially biased, point of view.
A real-world case study at LinkedIn demonstrated the effectiveness of this approach. By using an LLM-as-a-Judge system with ChainPoll, they were able to automate a significant portion of their content quality evaluations, achieving over 90% agreement with human raters at a fraction of the time and cost.
Small Language Models as Judges
While larger models like Google’s Gemini 2.5 are the gold standard for complex, nuanced evaluations, the role of specialised Small Language Models (SLMs) is rapidly gaining traction. SLMs are smaller, more focused models that are fine-tuned for a specific evaluation task, offering several key advantages over their larger counterparts.
- Enhanced Focus: An SLM trained exclusively on a narrow evaluation task can often outperform a general-purpose LLM on that specific metric.
- Deployment Flexibility: Their small size makes them ideal for on-device or edge deployment, enabling real-time, low-latency evaluation.
- Production Readiness: SLMs are more stable, predictable, and easier to integrate into production pipelines.
- Cost-Efficiency: The cost per inference is significantly lower, making them highly economical for large-scale, high-frequency evaluations.
Galileo’s latest offering, Luna 2, exemplifies this trend. Luna 2 is a new generation of SLM specifically designed to provide low-latency, low-cost metric evaluations. Its architecture is optimized for speed and accuracy, making it an ideal candidate for tasks such as sentiment analysis, toxicity detection, and basic factual verification where a large, expensive LLM may be overkill.
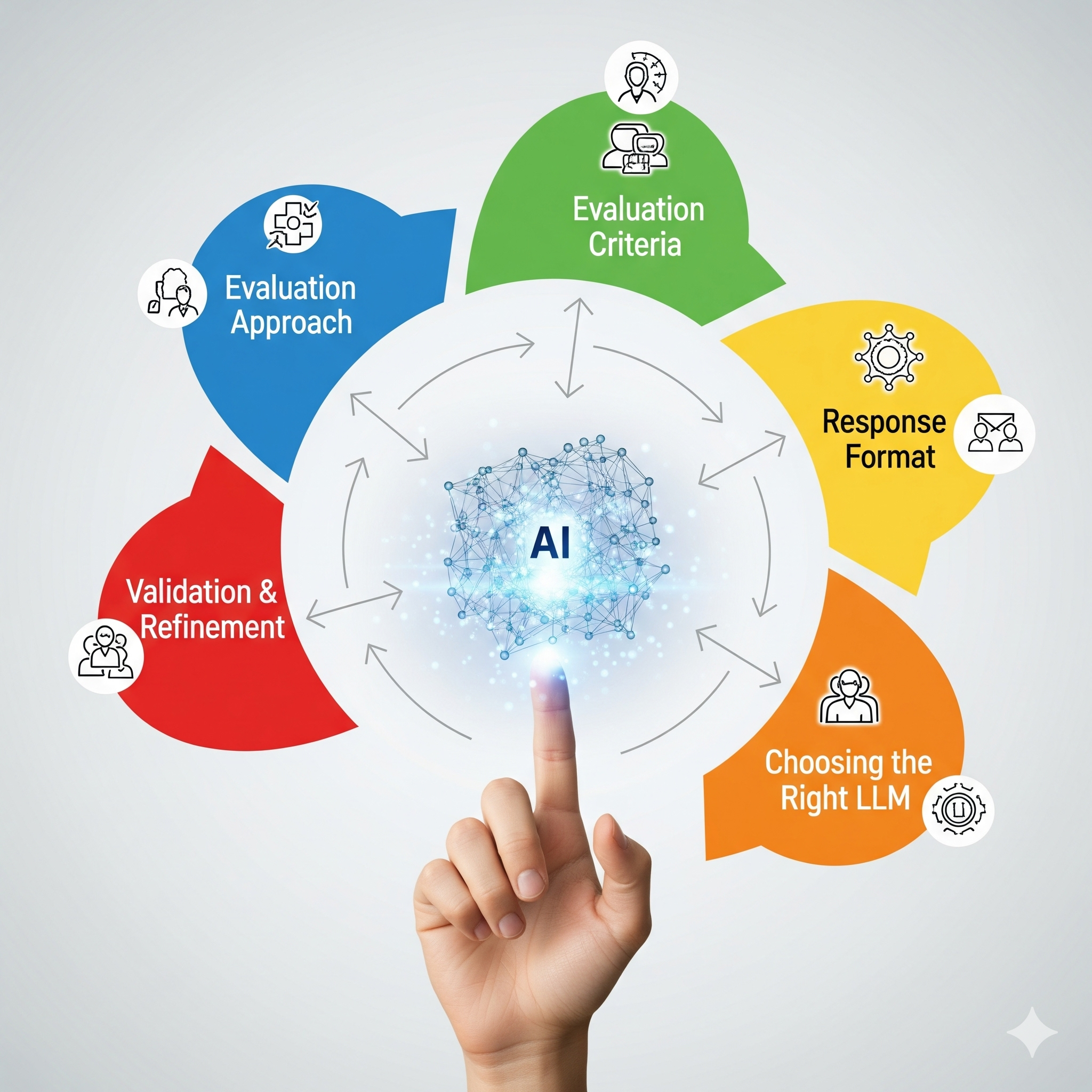
Best Practices for Creating Your LLM-as-a-Judge
Building a reliable LLM judge is an art and a science. It requires a thoughtful approach to five key components.
- Evaluation Approach: Decide whether a simple scoring system (e.g., 1-5 scale) or a more sophisticated ranking and comparison system is best. Consider a multidimensional system that evaluates on multiple criteria.
- Evaluation Criteria: Clearly and precisely define the metrics you are assessing. These could include factual accuracy, clarity, adherence to context, tone, and formatting requirements. The prompt must be unambiguous.
- Response Format: The judge’s output must be predictable and machine-readable. A discrete scale (e.g., 1-5) or a structured JSON output is ideal. JSON is particularly useful for multidimensional assessments.
- Choosing the Right LLM: The choice of the base LLM for your judge is perhaps the most critical decision. Models must balance performance, cost, and task specificity. While smaller models like Luna 2 excel at specific tasks, a robust general-purpose model like Google’s Gemini 2.5 has proven to be exceptionally effective as a judge due to its unparalleled reasoning capabilities and broad contextual understanding.
- Other Considerations: Account for bias detection, consistency (e.g., by testing the same input multiple times), edge case handling, interpretability of results, and overall scalability.
A Conceptual Code Example for a Core Judge
The following is a simplified, conceptual example of how a core LLM judge function might be configured:
def create_llm_judge_prompt(evaluation_criteria, user_query, candidate_responses):
"""
Constructs a detailed prompt for an LLM judge.
"""
prompt = f"""
You are an expert evaluator of AI responses. Your task is to judge and rank the following responses
to a user query based on the following criteria:
Criteria:
{evaluation_criteria}
User Query:
"{user_query}"
Candidate Responses:
Response A: "{candidate_responses['A']}"
Response B: "{candidate_responses['B']}"
Instructions:
1. Think step-by-step and write your reasoning.
2. Based on your reasoning, provide a final ranking of the responses.
3. Your final output must be in JSON format: {{"reasoning": "...", "ranking": {{"A": "...", "B": "..."}}}}
"""
return prompt
def validate_llm_judge(judge_function, test_data, metrics):
"""
Validates the performance of the LLM judge against a human-labeled dataset.
"""
judgements = []
for test_case in test_data:
prompt = create_llm_judge_prompt(test_case['criteria'], test_case['query'], test_case['responses'])
llm_output = judge_function(prompt) # This would be your API call to Gemini 2.5
judgements.append({
'llm_ranking': llm_output['ranking'],
'human_ranking': test_case['human_ranking']
})
# Calculate metrics like precision, recall, and Cohen's Kappa
# based on the judgements list.
return calculate_metrics(judgements, metrics)
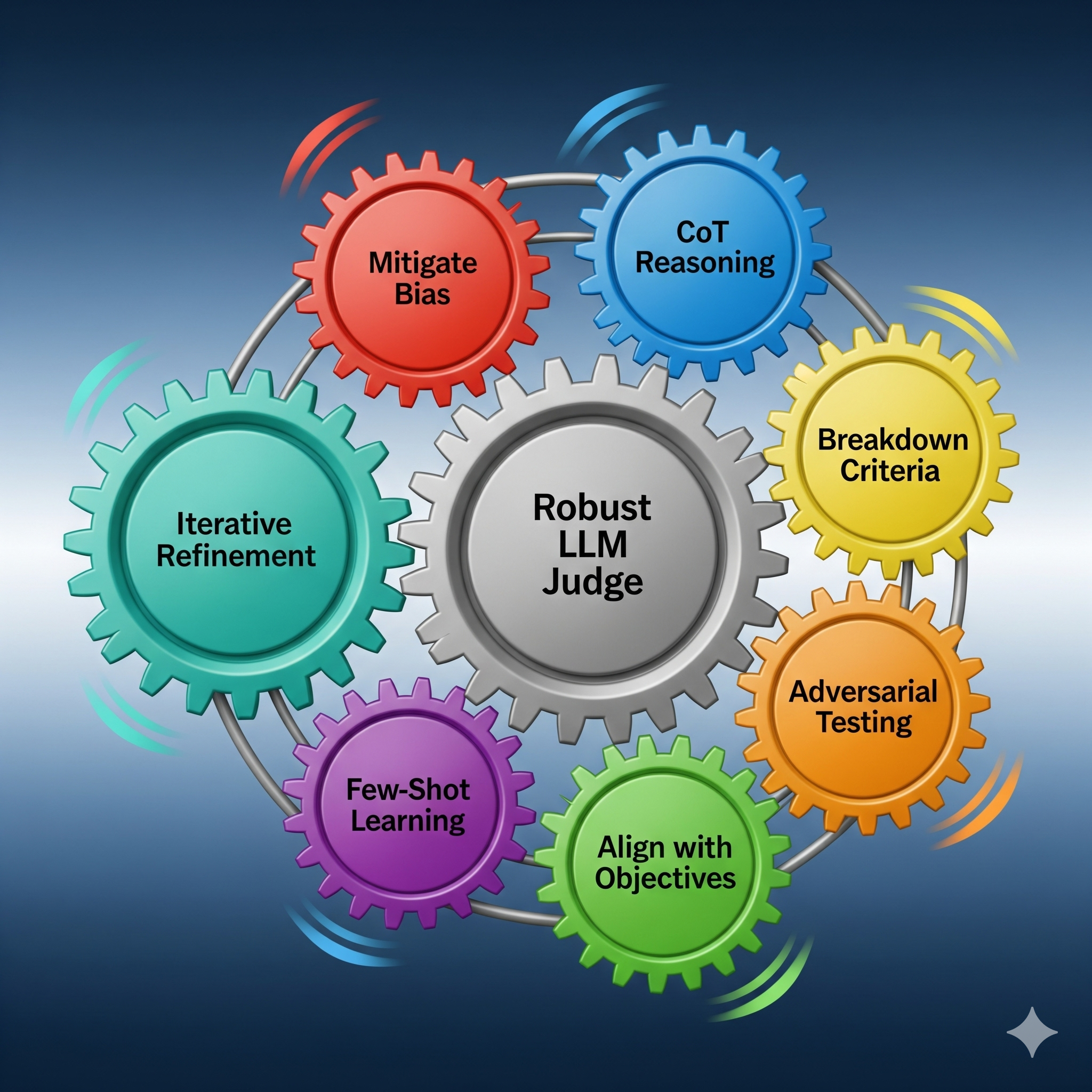
Tricks to Improve LLM-as-a-Judge
Building upon the foundational best practices, there are seven practical enhancements that can dramatically improve the reliability and consistency of your LLM judge.
- Mitigate Evaluation Biases: As discussed, biases are a constant threat. Use techniques like varying the response sequence for positional bias and polling multiple LLMs to combat nepotism.
- Enforce Reasoning with CoT Prompting: Always instruct your judge to “think step-by-step.” This forces the model to explain its logic, making its decisions more transparent and often more accurate.
- Break Down Criteria: Instead of a single, ambiguous metric like “quality,” break it down into granular components such as “factual accuracy,” “clarity,” and “creativity.” This allows for more targeted and precise assessments.
- Align with User Objectives: The LLM judge’s prompts and criteria should directly reflect what truly matters to the end user. An output that is factually correct but violates the desired tone is not a good response.
- Utilise Few-Shot Learning: Providing the judge with a few well-chosen examples of good and bad responses, along with detailed explanations, can significantly improve its understanding and performance on new tasks.
- Incorporate Adversarial Testing: Actively create and test with intentionally difficult or ambiguous edge cases to challenge your judge and identify its weaknesses.
- Implement Iterative Refinement: Evaluation is not a one-time process. Continuously track inconsistencies, review challenging responses, and use this data to refine your prompts and criteria.
By synthesizing these strategies into a comprehensive toolbox, we can build a highly robust and reliable LLM judge. Ultimately, the effectiveness of any LLM-as-a-Judge system is contingent on the underlying model’s reasoning capabilities and its ability to handle complex, open-ended tasks. While many models can perform this function, our extensive research and testing have consistently shown that Google’s Gemini 2.5 outperforms its peers in the majority of evaluation scenarios. Its advanced reasoning and nuanced understanding of context make it the definitive choice for building an accurate, scalable, and sophisticated evaluation framework.